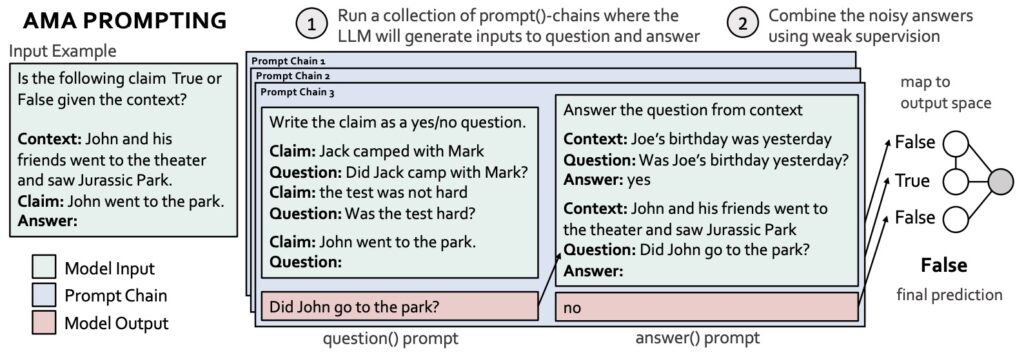
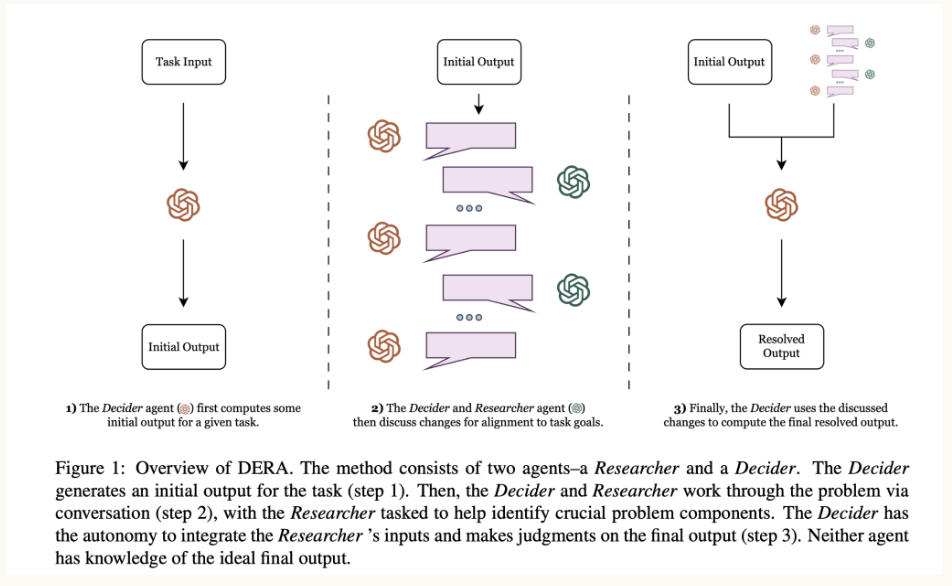
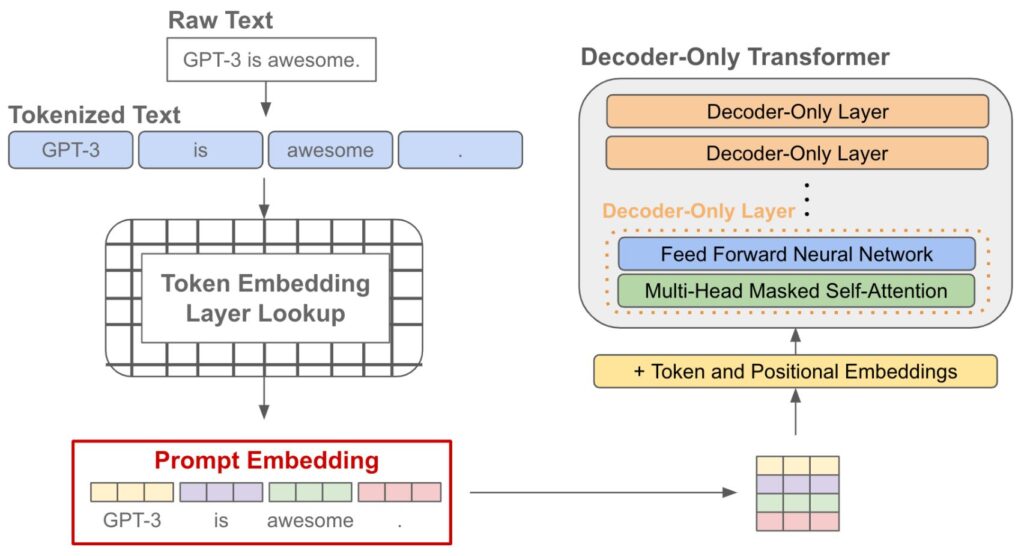
# Vyhledávání informací
Generativní AI dokáže bleskově procházet velké objemy zdrojů, vyhledat relevantní data a vrátit je ve srozumitelném souhrnu. Ušetří tak hodiny manuálního vyhledávání a pomůže odhalit i skrytá spojení mezi informacemi.
# Výzkum a analýza
Modely LLM umí syntetizovat akademické studie, zprávy či interní dokumenty a vytvářet z nich přehledné analýzy, grafy i doporučení. Dokážou odhalit vzorce, trendy a slabá místa, která by lidskému týmu snadno unikla.
# Extrakce dat
AI vytáhne konkrétní fakta, čísla nebo klíčové fráze z nestrukturovaných textů, e‑mailů či skenů. Výsledkem je čistá tabulka nebo databáze připravená k dalšímu zpracování a automatizaci procesů.
# Interpretace faktů a historie
Generativní AI umí zasadit fakta do kontextu, vysvětlit historické souvislosti a předložit ucelený příběh. Vhodně kombinuje chronologii, kauzalitu i relevantní citace, čímž zjednoduší pochopení složitých událostí.
# Kategorizace a klasifikace
Díky strojovému učení lze dokumenty, obrázky či produkty automaticky přiřazovat do správných kategorií. AI se přizpůsobí firemní taxonomii a zlepšuje přesnost s každým dalším příkladem.
# Překlady a transformace
Modely zvládají vícejazyčné překlady, ale i úpravy tónu, stylu či formátu textu. Umí tak rychle vytvořit lokalizované materiály nebo převést neformální zápisky do profesionálního stylu.
# Programování a kódování
Generativní AI navrhuje funkce, generuje celé bloky kódu a pomáhá s laděním či refaktoringem. Umožňuje tak vývojářům soustředit se na architekturu a logiku místo repetitivního psaní stavebních kamenů.
# Korektura a formátování
Automaticky odhalí gramatické chyby, zlepší stylistiku a sjednotí formát dokumentu podle vybraných pravidel. Výsledkem je profesionálně upravený text bez ručního pročítání.
# Optimalizace a dokumentace
AI umí analyzovat procesy, navrhnout zjednodušení a vytvořit detailní dokumentaci či návody. Zkracuje tak dobu zaškolení nováčků a zajišťuje konzistentní know‑how v týmu.
# Generování nápadů
Při brainstormingu dokáže AI generovat pestrou škálu originálních konceptů, sloganů či produktových funkcí. Inspiruje týmy k novým směrům, které by je samy nemusely napadnout.
# Generování názorů
Modely umí formulovat argumenty pro i proti, hodnotit rizika a přinášet různé perspektivy na dané téma. Usnadňují tak tvorbu expertních posudků, recenzí nebo rozhodovacích podkladů.
# Simulace chování
AI dokáže napodobit reakce různých uživatelských person, zákazníků či aktérů v modelových situacích. Pomáhá testovat chatboty, marketingové kampaně i krizové scénáře bez nutnosti nákladných pilotů.
# Generování textů
Od krátkých příspěvků na sociální sítě až po rozsáhlé články – generativní AI vytvoří čtivý obsah na míru publiku i zadání. Výsledný text lze dále ladit, zkracovat či doplňovat o fakta.
# Generování obsahu podle vzorů
Při znalosti šablony dokáže AI vyplnit všechny potřebné sekce, například smlouvy, e‑maily či reporty. Zajišťuje tak konzistenci a zkracuje čas potřebný na přípravu rutinních dokumentů.
# Předpovědi a dokončení
Modely predikují nejpravděpodobnější pokračování textu, kódu nebo dialogu a umožňují rychlé autocomplety. V oblasti dat navíc odhadují budoucí trendy či chování na základě historických vzorců.