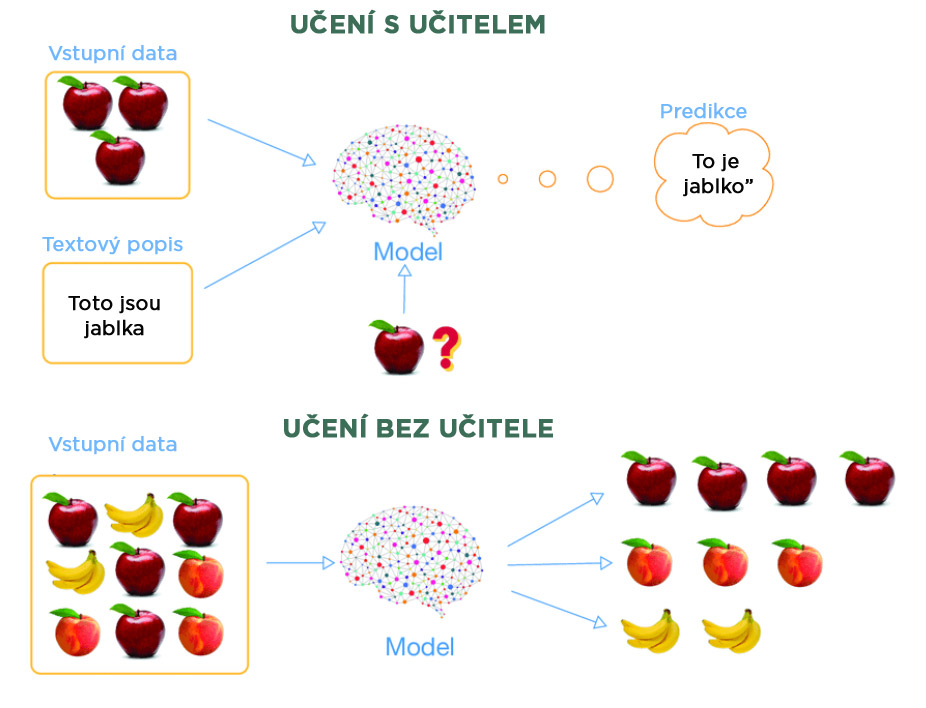
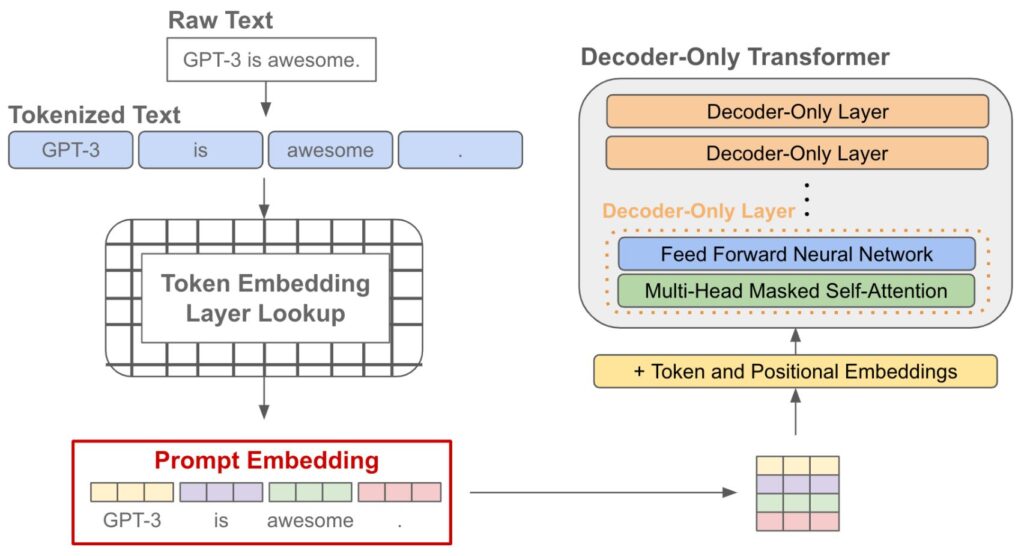
# Vyhledávání informací
Generativní AI dokáže bleskově procházet velké objemy zdrojů, vyhledat relevantní data a vrátit je ve srozumitelném souhrnu. Ušetří tak hodiny manuálního vyhledávání a pomůže odhalit i skrytá spojení mezi informacemi.
Příklady praktických promptů:
1. Rychlý research konkurence:
Vyhledej všechny klíčové informace o firmě [název konkurenta]
z veřejně dostupných zdrojů a shrň jejich hlavní produkty,
cílovou skupinu, cenovou politiku a nedávné novinky.
Výsledek strukturuj do přehledné tabulky.
2. Analýza trendů v oboru:
Projdi poslední zprávy a články o [téma/technologie] z posledních
6 měsíců a identifikuj 5 hlavních trendů. U každého trendu uveď
konkrétní příklady a zdroje.
Pro efektivní využití AI ve výzkumu konkurence doporučujeme naši službu výzkum konkurence, která kombinuje automatizované nástroje s expertní analýzou.
# Výzkum a analýza
Modely LLM umí syntetizovat akademické studie, zprávy či interní dokumenty a vytvářet z nich přehledné analýzy, grafy i doporučení. Dokážou odhalit vzorce, trendy a slabá místa, která by lidskému týmu snadno unikla.
Příklady analytických promptů:
1. Analýza zákaznických recenzí:
Analyzuj přiložených 200 zákaznických recenzí a identifikuj:
- 5 nejčastějších pochval
- 5 nejčastějších stížností
- Skrytá témata, která se opakují
- Doporučení pro zlepšení produktu
Výsledky zobraz v grafech a tabulkách.
2. Komparativní studie řešení:
Porovnej 3 různé přístupy k [problém/úkol] na základě kritérií:
náklady, časová náročnost, efektivita, rizika. Vytvoř bodové
hodnocení a doporuč nejlepší řešení s odůvodněním.
Pro pokročilé analytické úkoly nabízíme prediktivní analýzu, která využívá AI k předpovídání budoucího vývoje na základě historických dat.
# Extrakce dat
AI vytáhne konkrétní fakta, čísla nebo klíčové fráze z nestrukturovaných textů, e‑mailů či skenů. Výsledkem je čistá tabulka nebo databáze připravená k dalšímu zpracování a automatizaci procesů.
Příklady extrakčních promptů:
1. Získání kontaktů z dokumentů:
Z přiloženého PDF dokumentu vytáhni všechny:
- Jména osob a jejich role
- E-mailové adresy
- Telefonní čísla
- Adresy firem
Výsledek vrať jako CSV tabulku.
2. Extrakce klíčových metrik:
Projdi tento obchodní report a vytvoř strukturovaný přehled
obsahující: měsíční tržby, počet nových zákazníků, průměrnou
hodnotu objednávky, konverzní poměr. Zobraz data v časové řadě.
Pro automatizaci extrakce dat z webů využijte automatizaci s Make.com, která dokáže pravidelně sbírat a zpracovávat data bez manuálního zásahu.
# Interpretace faktů a historie
Generativní AI umí zasadit fakta do kontextu, vysvětlit historické souvislosti a předložit ucelený příběh. Vhodně kombinuje chronologii, kauzalitu i relevantní citace, čímž zjednoduší pochopení složitých událostí.
Příklady interpretačních promptů:
1. Kontextualizace událostí:
Vysvětli vliv [historická událost] na [současný stav/trend]
v kontextu [obor/region]. Zahrň klíčové milníky, hlavní aktéry
a dlouhodobé důsledky. Použij timeline formát.
2. Analýza kauzality:
Na základě poskytnutých dat vysvětli příčinné souvislosti mezi
[událost A] a [událost B]. Identifikuj přímé i nepřímé faktory
a ohodnoť jejich vliv na stupnici 1-10.
Pro hlubší pochopení dat doporučujeme analýzu sentimentu, která odhaluje emocionální podtext v textech a pomáhá lépe interpretovat názory zákazníků.
# Kategorizace a klasifikace
Díky strojovému učení lze dokumenty, obrázky či produkty automaticky přiřazovat do správných kategorií. AI se přizpůsobí firemní taxonomii a zlepšuje přesnost s každým dalším příkladem.
Příklady klasifikačních promptů:
1. Třídění dokumentů:
Zkategorizuj následující dokumenty do skupin: faktury, smlouvy,
objednávky, reklamace, ostatní. Pro každou kategorii uveď
stručný důvod zařazení a úroveň jistoty (%).
2. Segmentace zákazníků:
Na základě těchto zákaznických dat (věk, nákupní historie,
hodnota košíku, frekvence nákupů) vytvoř 4-5 zákaznických
segmentů. Každý segment pojmenuj a popiš jeho charakteristiky.
Efektivní segmentaci trhu využívá naše služba segmentace trhu, která kombinuje AI analýzu s marketingovým know-how pro přesné zacílení kampaní.
# Překlady a transformace
Modely zvládají vícejazyčné překlady, ale i úpravy tónu, stylu či formátu textu. Umí tak rychle vytvořit lokalizované materiály nebo převést neformální zápisky do profesionálního stylu.
Příklady transformačních promptů:
1. Lokalizace obsahu:
Přelož následující marketingový text do němčiny a přizpůsob ho
německému trhu - použij formální tón, lokální reference a upravit
příklady tak, aby rezonovaly s německými zákazníky.
2. Změna stylu dokumentu:
Převeď tyto neformální poznámky z meetingu do profesionálního
formátu business reportu. Zachovej všechny klíčové informace,
ale uprav jazyk, strukturu a přidej executive summary.
Pro kvalitní překlady doporučujeme využít nástroj AI překladač, který kombinuje strojové učení s kontextovým porozuměním pro přesné překlady.
# Programování a kódování
Generativní AI navrhuje funkce, generuje celé bloky kódu a pomáhá s laděním či refaktoringem. Umožňuje tak vývojářům soustředit se na architekturu a logiku místo repetitivního psaní stavebních kamenů.
Příklady programovacích promptů:
1. Generování API endpointu:
Vytvoř REST API endpoint v Python Flask pro registraci uživatele.
Endpoint by měl validovat email, hashovat heslo pomocí bcrypt,
ukládat do PostgreSQL databáze a vracet JWT token. Zahrň error handling.
2. Refaktoring legacy kódu:
Refaktoruj tento JavaScript kód: [vložit kód]. Použij moderní
ES6+ syntaxi, rozděl do menších funkcí, přidej TypeScript typy
a navrhni unit testy. Vysvětli změny a důvody.
Moderní přístup ke kódování s AI představuje vibe coding, který kombinuje lidskou kreativitu s výkonem AI pro rychlejší vývoj aplikací.
# Korektura a formátování
Automaticky odhalí gramatické chyby, zlepší stylistiku a sjednotí formát dokumentu podle vybraných pravidel. Výsledkem je profesionálně upravený text bez ručního pročítání.
Příklady korekturních promptů:
1. Komplexní revize textu:
Zkontroluj tento text a oprav: gramatické chyby, pravopisné chyby,
interpunkci, stylistiku. Zlepši čitelnost, odstraň redundance
a zajisti konzistentní formátování. Vrať upravený text s vysvětlením změn.
2. Adaptace na cílovou skupinu:
Přepiš tento technický dokument pro netechnické publikum.
Zjednodušit jazyk, nahradit žargon běžnými výrazy, přidat příklady
z praxe a zajistit, aby byl text srozumitelný pro laiky.
Pro profesionální zpracování marketingových textů využijte naši službu AI copywriting, která kombinuje AI technologie s expertním copywritingem.
# Optimalizace a dokumentace
AI umí analyzovat procesy, navrhnout zjednodušení a vytvořit detailní dokumentaci či návody. Zkracuje tak dobu zaškolení nováčků a zajišťuje konzistentní know‑how v týmu.
Příklady optimalizačních promptů:
1. Analýza pracovního procesu:
Analyzuj tento firemní proces: [popis procesu]. Identifikuj
úzká místa, nadbytečné kroky a navrhni optimalizace. Vytvoř
nový proces diagram s časovými úsporami a odhadovanými náklady implementace.
2. Tvorba onboarding dokumentace:
Vytvoř kompletní onboarding dokumentaci pro nové vývojáře v našem týmu.
Zahrň: nastavení vývojového prostředí, přehled architektury,
coding standards, git workflow, deployment proces. Formát: krok za krokem.
Pro vytváření konzistentní procesní dokumentace doporučujeme využít standardní operační postup, který zajistí jednotný přístup k dokumentaci napříč celou firmou.
# Generování nápadů
Při brainstormingu dokáže AI generovat pestrou škálu originálních konceptů, sloganů či produktových funkcí. Inspiruje týmy k novým směrům, které by je samy nemusely napadnout.
Příklady kreativních promptů:
1. Brainstorming produktových funkcí:
Vygeneruj 20 inovativních funkcí pro mobilní aplikaci [typ aplikace].
Zaměř se na: zlepšení uživatelské zkušenosti, AI funkce,
gamifikaci, sociální prvky. U každé funkce uveď benefit a složitost implementace.
2. Tvorba marketingových sloganů:
Vytvoř 15 reklamních sloganů pro [produkt/službu]. Slogany by měly být:
krátké (max 7 slov), zapamatovatelné, vtipné nebo emotivní,
zdůrazňovat hlavní benefit. Navrhni i 3 varianty pro různé cílové skupiny.
Pro systematický přístup ke kreativnímu psaní využijte vzorce pro psaní přesvědčivých textů, které kombinují osvědčené principy s AI generováním.
# Generování názorů
Modely umí formulovat argumenty pro i proti, hodnotit rizika a přinášet různé perspektivy na dané téma. Usnadňují tak tvorbu expertních posudků, recenzí nebo rozhodovacích podkladů.
Příklady argumentačních promptů:
1. Vyvážená analýza rozhodnutí:
K rozhodnutí [popis situace] vytvoř analýzu pro/proti.
Pro každou stranu uveď 5 silných argumentů, ohodnoť rizika
a příležitosti, přidej reálné příklady a doporuč finální postoj
s odůvodněním.
2. Multi-perspektivní pohled:
K tématu [téma] vytvoř názory z pohledu 4 různých stakeholderů:
zákazník, investor, zaměstnanec, konkurence. U každého pohledu
vysvětli jejich priority, obavy a očekávání.
Pro strukturované uvažování a argumentaci využijte techniku Chain of Thought, která pomáhá AI generovat logicky provázané a zdůvodněné závěry.
# Simulace chování
AI dokáže napodobit reakce různých uživatelských person, zákazníků či aktérů v modelových situacích. Pomáhá testovat chatboty, marketingové kampaně i krizové scénáře bez nutnosti nákladných pilotů.
Příklady simulačních promptů:
1. Testování customer support scénářů:
Simuluj konverzaci mezi zákazníkem a support chatbotem. Zákazník:
rozhněvaný, technicky nezkušený, má problém s [produkt].
Chatbot by měl problém vyřešit do 5 zpráv. Vytvoř 3 různé verze konverzace.
2. Persona-based marketing test:
Vytvoř 3 user persony pro [produkt/službu] a simuluj jejich reakci
na marketingovou kampaň [popis kampaně]. U každé persony uveď:
demografii, motivace, bolesti, pravděpodobnou reakci a konverzní potenciál.
Praktické využití chatbotů pro různé scénáře popisuje článek role AI chatbota v sektoru vzdělávání, který ukazuje reálné příklady simulace interakcí.
# Generování textů
Od krátkých příspěvků na sociální sítě až po rozsáhlé články – generativní AI vytvoří čtivý obsah na míru publiku i zadání. Výsledný text lze dále ladit, zkracovat či doplňovat o fakta.
Příklady textových promptů:
1. LinkedIn post s engagement:
Napiš LinkedIn příspěvek o [téma] pro [cílovou skupinu].
Post by měl: začínat hookem, být max 150 slov, obsahovat osobní zkušenost,
mít jasný CTA, používat hashtags. Tón: profesionální ale přátelský.
2. SEO-optimalizovaný článek:
Vytvoř článek (1500 slov) o [téma]. Struktura: úvod s hooks,
5 H2 nadpisů, praktické příklady, bullet pointy, závěr s CTA.
Zahrň klíčová slova: [seznam KW]. Tón: expertní ale srozumitelný.
Pro efektivní tvorbu AI promptů využijte kompletní přehled prompt engineering techniky, které maximalizují kvalitu generovaných textů.
# Generování obsahu podle vzorů
Při znalosti šablony dokáže AI vyplnit všechny potřebné sekce, například smlouvy, e‑maily či reporty. Zajišťuje tak konzistenci a zkracuje čas potřebný na přípravu rutinních dokumentů.
Příklady šablonových promptů:
1. Generování obchodního emailu:
Použij tuto šablonu follow-up emailu: [šablona].
Vyplň pro klienta [jméno firmy], který projevil zájem o [produkt].
Zahrň: personalizovaný úvod, rekapitulaci meetingu, next steps,
deadline. Tón: profesionální ale ne agresivní.
2. Měsíční reportovací template:
Vytvoř měsíční report podle této struktury: [struktura].
Data: [klíčové metriky]. Report by měl obsahovat: executive summary,
grafy trendů, porovnání s minulým měsícem, doporučení pro další období.
Systematický přístup k práci se šablonami nabízí technika template-based prompting, která zajišťuje konzistentní a kvalitní výstupy.
# Předpovědi a dokončení
Modely predikují nejpravděpodobnější pokračování textu, kódu nebo dialogu a umožňují rychlé autocomplety. V oblasti dat navíc odhadují budoucí trendy či chování na základě historických vzorců.
Příklady prediktivních promptů:
1. Predikce tržních trendů:
Na základě těchto historických dat [data] předpověz vývoj [metriky]
pro příštích 6 měsíců. Zahrň: očekávaný trend, seasonality,
rizikové faktory, confidence interval. Vizualizuj ve formátu grafu.
2. Dokončení code snippetu:
Dokonči tuto funkci: [neúplný kód]. Funkce by měla [popis funkcionality].
Použij best practices, přidej error handling, docstring a navrhni
2-3 unit testy. Vysvětli logiku implementace.
Pro pokročilé prediktivní úlohy doporučujeme techniku retrieval augmented generation, která kombinuje AI model s externími znalostními bázemi pro přesnější předpovědi.