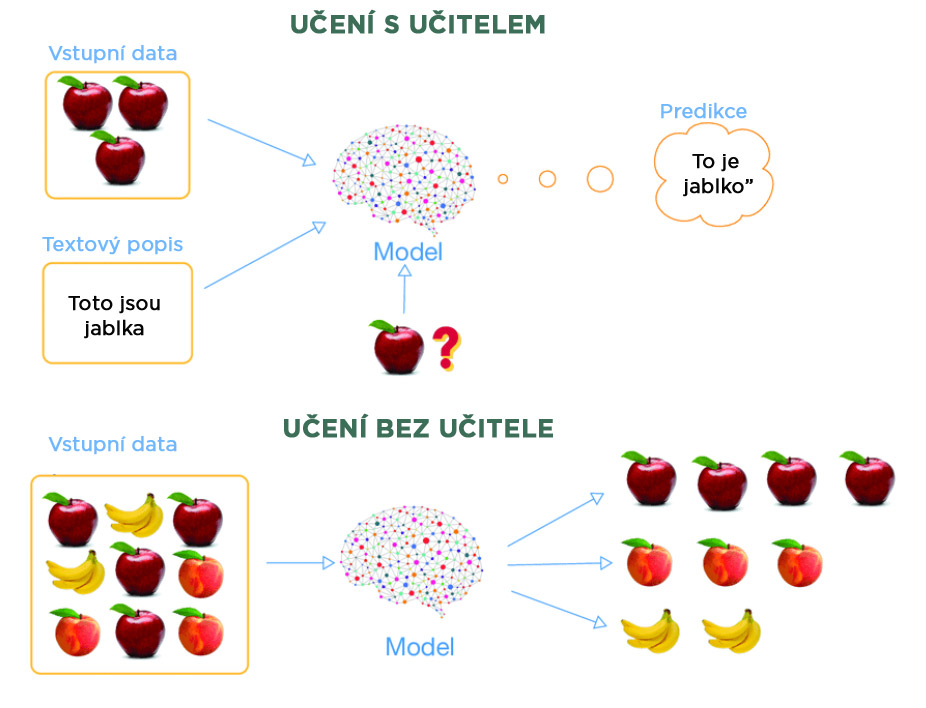
Učení s učitelem (supervised learning) zahrnuje trénovací sadu, která obsahuje označená data, a cílem je najít mapovací funkci, která převádí vstupy na požadované výstupy.
Například model dostane datovou sadu – řekněme ovoce. Shromáždí všechny informace, jako je tvar, velikost, chuť a název ovoce, a učí se z každého typu dat. Jakmile je model vytrénován, je mu předložen nový druh ovoce (testovací data) a na základě trénovacích dat model předpoví název ovoce podle analýzy všech dříve naučených informací.
Učení bez učitele (unsupervised learning) na rozdíl od toho vykazuje samoorganizaci. Algoritmus pracuje s neoznačenými a neklasifikovanými daty a jeho úkolem je v nich najít skryté vlastnosti nebo struktury. Zahrnuje například seskupování dat do skupin (klastrů) na základě podobností, vzorců nebo rozdílů bez jakéhokoli předchozího vedení.
Například model dostane neoznačená data obrázků koček a psů. Model data rozdělí do dvou různých klastrů, aniž by znal jejich označení. Když je mu následně předložen nový obrázek kočky (testovací data), na základě získaných znalostí jej zařadí do klastru koček.
Učení s učitelem je třída metod strojového učení, která stojí v opozici proti učení bez učitele. Trénovací data se přitom sestávají ze vstupních objektů (vektorů jejich příznaků) a jejich požadovaných výstupních ohodnocení, tj. závisle proměnných (obecně také ve tvaru vektorů), tj. výroků učitele o objektu.
Výstupem naučené funkce (jejíž příklady jsou obsaženy v trénovacích datech) pak mohou být spojité hodnoty (při regresi) anebo binární hodnoty označující příslušnost vstupních objektů do daných tříd (při klasifikaci). Naučená funkce pak dokáže odhadovat výstupní ohodnocení každého vstupního objektu (i neobsaženého v trénovacích datech) poté, co zpracuje trénovací příklady (tj. dvojice vstup a požadovaný výstup). Aby to dokázala, musí umět zobecnit (generalizovat) souvislost mezi vstupy a výstupy danou příklady obsaženými v trénovacích datech „smysluplným“ způsobem.[1] (Porovnejte s učením bez učitele.)
Přeučení
Overfitting neboli přeučení je stav, kdy je systém příliš přizpůsoben množině trénovacích dat, ale nemá schopnost generalizace a selhává na validační množině dat. To se může stát např. při malém rozsahu trénovací množiny nebo pokud je systém příliš komplexní, např. příliš mnoho skrytých neuronů v neuronové síti. Řešením je zvětšení trénovací množiny, snížení složitosti systému nebo různé techniky regularizace, jako je zavedení náhodného šumu (což v zásadě odpovídá rozšíření trénovací množiny), zavedení omezení na parametry systému, které v důsledku snižuje složitost popisu naučené funkce, nebo předčasné ukončení učení (průběžné sledování chyby na validační množině a konec učení ve chvíli, kdy se chyba na této množině dostane do svého minima).
Trénovací data
Trénovací data jsou data (v konkrétní počítačové podobě například databáze nebo adresář se soubory), na kterých se v umělé inteligenci nebo strojovém učení odhadují parametry a/nebo struktura modelu. Trénovací data se skládají ze vstupního vektoru (množiny) dat a v případě učení s učitelem také odpovídajícího výstupního vektoru dat.
Pro správné naučení inteligentního systému je obvykle potřeba dostatečně reprezentativní množství trénovacích dat. Inteligentní systémy jsou v podstatě funkce, které ze vstupního vektoru vypočítají výstupní vektor a podle rozdílu od správného výstupního vektoru upraví své vnitřní parametry. Tento proces se opakuje, dokud není systém dostatečně naučen. Trénovací data se dle způsobu užití dělí do tří skupin:
Trénovací množina je sada dat, ve které algoritmus nachází určitý vztah, tj. provádí jejich (regresní analýzu), čímž se ‚učí‘.
Validační množina je sada dat, která se používají pro případnou úpravu parametrů učení ve snaze vyhnout se jeho ‚přeučení‘.
Testovací množina je sada dat, která se používají pro ověření kvality naučeného systému. Měla by být odlišná od trénovací resp. validační množiny. Systém je správně naučený tehdy, jestliže se shodnou úspěšností vyhodnocuje trénovací množinu i testovací množinu. Pokud má vyhodnocení trénovací množiny výrazně vyšší úspěšnost, je systém přeučený.
Reference
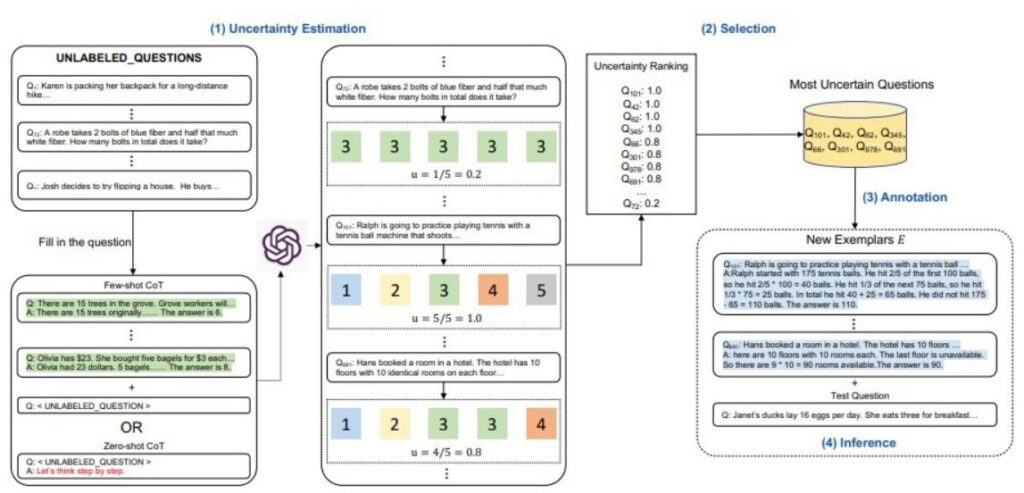
Schéma popisuje proces strojového učení s učitelem, konkrétně způsob, jakým model vyhodnocuje a třídí neoznačené otázky podle jejich nejistoty a následně je anotuje a používá pro inferenci.
Překlad do češtiny:
Odhad nejistoty
Neoznačené otázky:
- Qa: Karen si balí batoh na dlouhou túru.
- Qb: Rob si vezme 2 lahve modrého paliva a poloviční množství bílého paliva. Kolik lahví celkem vezme?
- Qc: Josh se rozhodne pro obrat domu. Koupí…
Vyplňte otázku:
- Qa: Jsou tam 15 stromů v háji. Pracovníci háje…
- Qb: Olivia má 32 dolarů. Koupila 5 tašek po 3 dolarech za každou. Olivia má nyní 2 dolary. Odpověď je 38.
Výběr
Seznam nejistot:
- Qa1: 1.0
- Qa2: 1.0
- Qa3: 0.8
- (a tak dále)
Nejvíce nejisté otázky:
- (Seznam otázek jako Qa1, Qa2, atd.)
Anotace
- Nové Příklady E:
- Qa1p: Ralph se chystá trénovat tenis s tenisovým míčkovým automatem, který střílí…
- Testovací Otázka:
- Qa1c: Hans rezervoval pokoj v hotelu. Hotel má 10 pater. Na každém patře je 10 pokojů. Poslední patro není dostupné. Kolik pokojů hotel má?
- Nové Příklady E:
Inference
- (Nezobrazeno na schématu)
https://blog.kore.ai/cobus-greyling/active-prompting-with-chain-of-thought-for-large-language-models