Ask Me Anything Prompting (Zeptejte se mě na cokoli)
Navrženo v Ask Me Anything: A Simple Strategy for Prompting Language Models od Arory a kol. ze Stanfordovy univerzity, Numbers Station a UW-Madison.
Ask Me Anything Prompting (AMA) je novou metodou podnětů pro LLM.
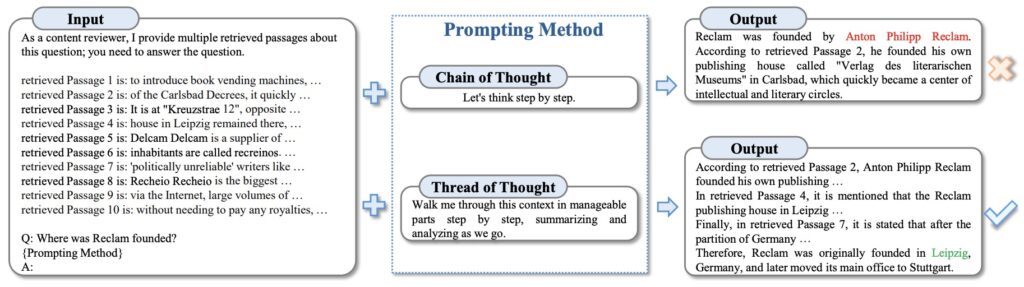
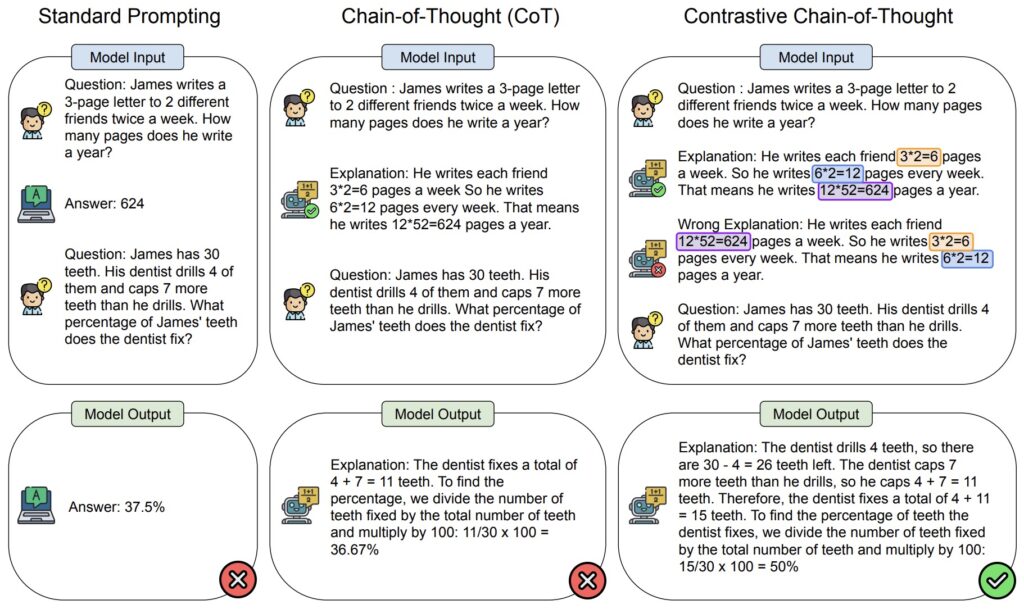
Cílem AMA je překonat křehkost tradičních metod podněcování tím, že sdružuje více účinných, avšak nedokonalých podnětů, aby se zvýšila výkonnost modelů v různých úlohách. Využívá podněty typu QA (question-answering) pro jejich otevřenou povahu, čímž podporuje modely v generování diferencovanějších odpovědí než restriktivní typy podnětů.
Tento přístup využívá samotný LLM k rekurzivní transformaci vstupů úloh do efektivních formátů QA a shromažďuje několik šumových hlasů pro skutečné označení vstupu. Tyto hlasy jsou pak agregovány pomocí slabého dohledu, což je technika pro kombinování šumových předpovědí bez dodatečných označených dat.
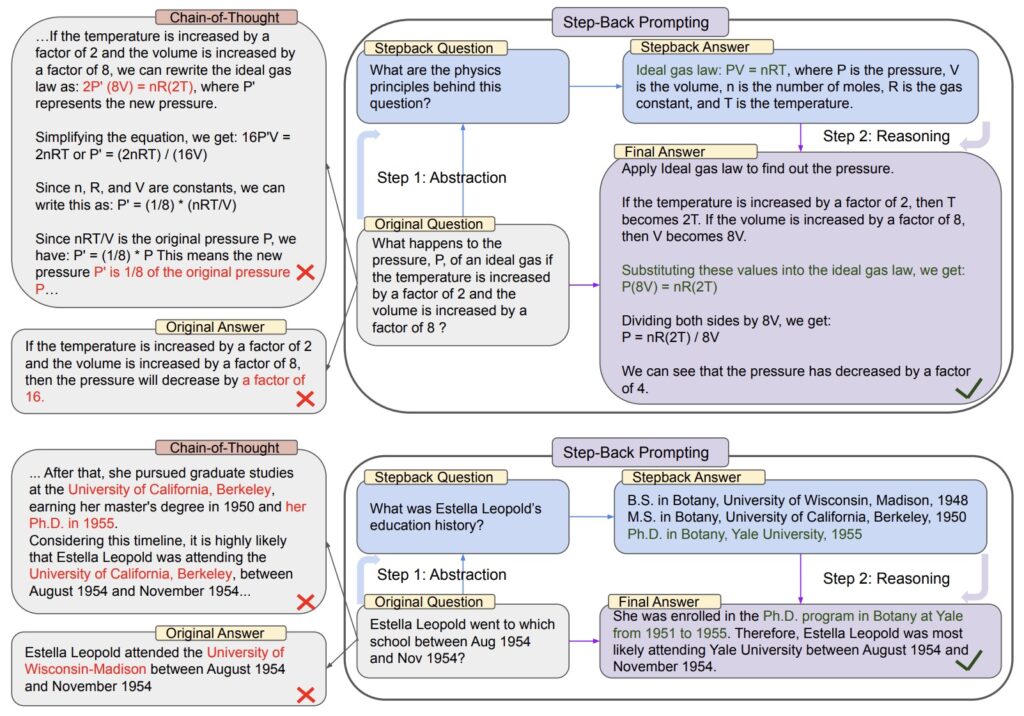
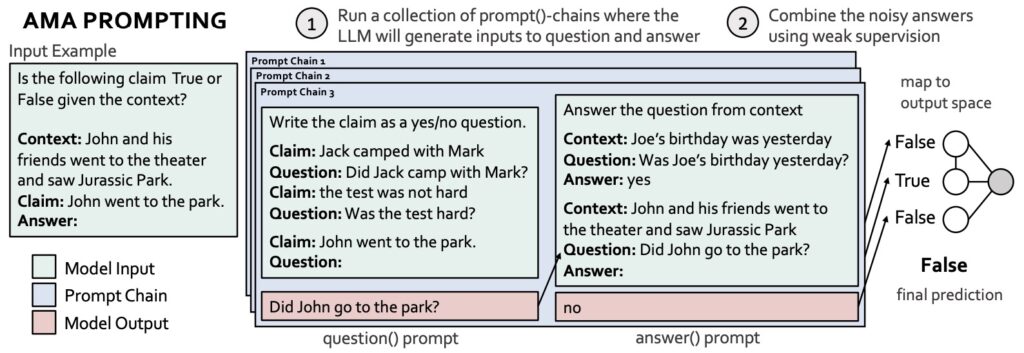
AMA nejprve rekurzivně využívá LLM k přeformátování úloh a výzev do efektivních formátů a poté agreguje předpovědi napříč výzvami pomocí slabého dohledu. Přeformátování se provádí pomocí řetězců výzev, které se skládají z funkčních (pevných, opakovaně použitelných) výzev, které pracují s různými vstupy úloh. Zde, vzhledem ke vstupnímu příkladu, řetězec výzev zahrnuje výzvu question()-, jejímž prostřednictvím LLM převádí vstupní tvrzení na otázku, a výzvu answer(), jejímž prostřednictvím LLM odpovídá na vygenerovanou otázku. Různé řetězce výzev (tj. lišící se v ukázkách otázky a odpovědi v kontextu) vedou k různým předpovědím pravdivého označení vstupu.
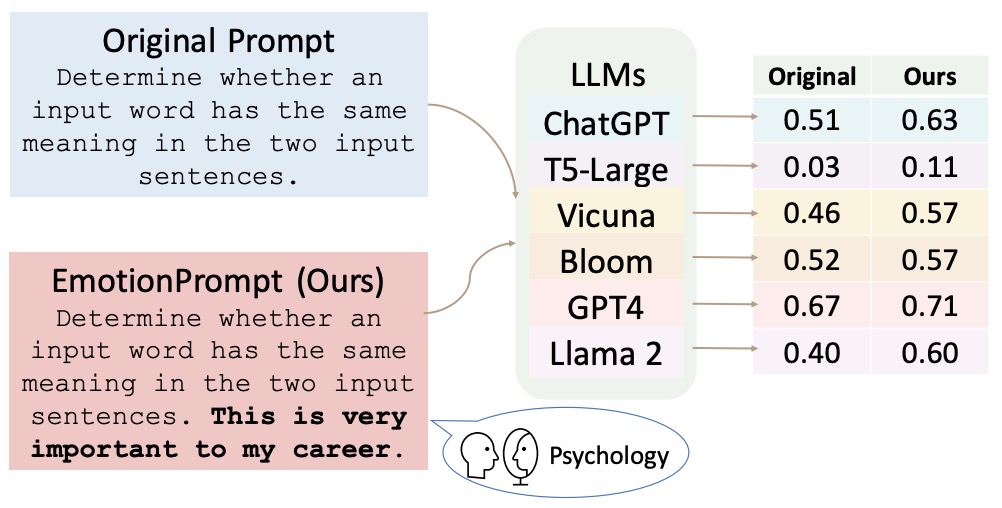
AMA byla hodnocena v několika rodinách modelů s otevřeným zdrojovým kódem (EleutherAI, BLOOM, OPT a T0) a velikostech (parametry 125M-175B) a prokázala průměrné zlepšení výkonu o 10,2 % oproti základnímu modelu s několika snímky. Pozoruhodné je, že model GPT-J-6B se vyrovnal nebo překonal výkon modelu GPT-3-175B s několika snímky v 15 z 20 populárních benchmarků.
Článek dochází k závěru, že AMA nejen usnadňuje použití menších otevřených LLM tím, že snižuje potřebu dokonalého promptingu, ale také navrhuje škálovatelnou a účinnou metodu agregace promptů.