Velké jazykové modely (LLM) vykazují působivý výkon při komplexním uvažování, protože využívají podněty myšlenkového řetězce (CoT) ke generování mezilehlých řetězců uvažování jako zdůvodnění pro odvození odpovědi. Dosavadní studie CoT se však zaměřovaly na modalitu jazyka.
Multimodal Chain-of-Thought Reasoning řeší omezení současných studií CoT v LLM tím, že zahrnuje jak jazykovou (text), tak zrakovou (obrázky) modalitu.
Multimodal-CoT je nový dvoustupňový rámec, který zlepšuje komplexní uvažování v LLM. Tento přístup nejprve generuje zdůvodnění pomocí textu i obrazů a poté tato vylepšená zdůvodnění využívá pro přesnější odvozování odpovědí. Tato metoda představuje významný odklon od dosavadních studií CoT, které se zaměřují pouze na jazykovou modalitu.
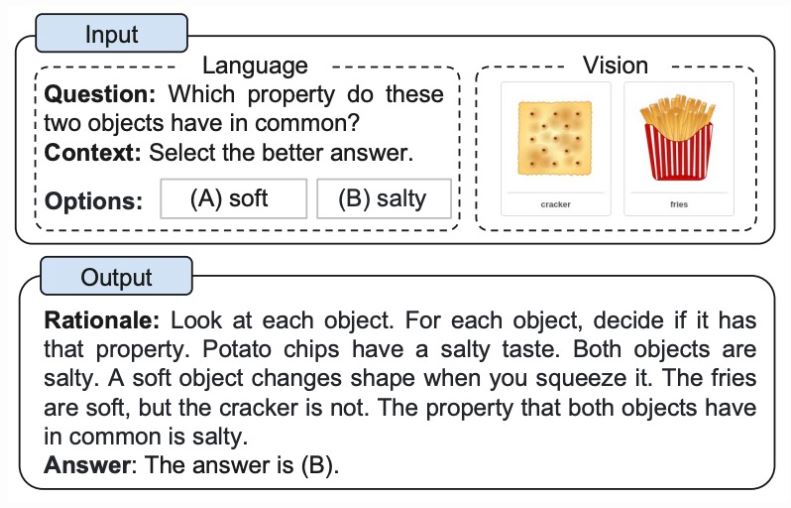
Následující obrázek z článku ukazuje příklad multimodální úlohy CoT.
Následující obrázek ukazuje Rámec Multimodal-CoT.
Multimodal-CoT se skládá ze dvou fází:
(i) generování zdůvodnění a
(ii) odvozování odpovědí.
Obě fáze mají stejnou architekturu modelu, ale liší se vstupem a výstupem.
V první fázi zásobují model jazykovými a zrakovými vstupy pro generování zdůvodnění.
Ve druhé fázi doplňují původní jazykový vstup o zdůvodnění vygenerované v první fázi.
Poté do modelu vloží aktualizovaný jazykový vstup s původním vstupem pro vidění, aby odvodili odpověď.

Zdroje:
Zhang a kol. ze Shanghai Jiao Tong University a Amazon Web Services, Multimodal-CoT