
Představte si to jako poskytnutí modelu „cestovní mapy“ myšlenek nebo kontextu, který ho vede k požadované odpovědi. Tato technika je obzvláště užitečná pro složitější úkoly, které vyžadují hlubší porozumění kontextu nebo pro úkoly, které vyžadují, aby model generoval odpovědi, které jsou konzistentní s předchozími informacemi nebo kontextem.
Pokud chcete, aby model napsal pokračování příběhu, můžete použít techniku Chain-of-thought k vytvoření kontextu, který modelu pomůže pochopit, co se stalo v příběhu dosud, jaké jsou charaktery postav, jaký je styl příběhu atd. Tímto způsobem model ví, jak pokračovat v příběhu tak, aby byl konzistentní s tím, co se stalo dosud.
co je výzva CoT? CoT prompting je jednoduchá technika pro zlepšení výkonu LLM při uvažování úloh, jako je zdravý rozum nebo symbolické uvažování. Výzva CoT využívá několikanásobné učení vložením několika příkladů problémů s uvažováním, které se řeší do výzvy. Každý příklad je spárován s myšlenkovým řetězcem (nebo zdůvodněním), který rozšiřuje odpověď na problém tím, že textově vysvětluje, jak je problém krok za krokem vyřešen zde:
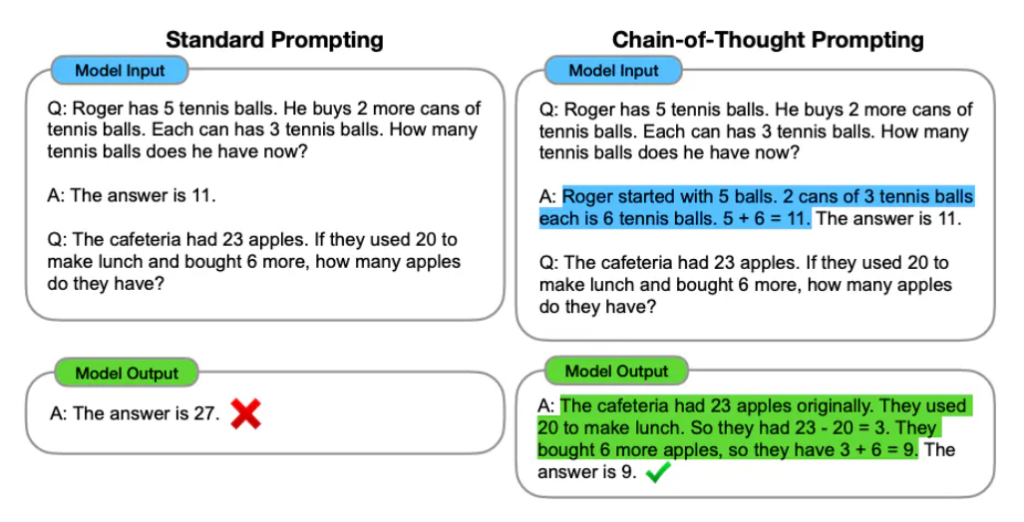
Obrázek ukazuje srovnání dvou přístupů k zadávání dotazů v kontextu modelů umělé inteligence, konkrétně Standard Prompting (Standardní zadávání) a Chain-of-Thought Prompting (Zadávání řetězce myšlenek).
Obrázek ilustruje, jak zadávání řetězce myšlenek může zlepšit schopnost modelu správně odpovídat na otázky tím, že model musí explicitně formulovat kroky vedoucí k závěru, což pomáhá jak při odhalování chyb, tak při poskytování srozumitelnějších odpovědí.
Díky schopnosti učit se po několika snímcích se mohou LLM naučit vytvářet zdůvodnění spolu se svými odpověďmi pozorováním příkladů v rámci výzvy CoT. Předchozí práce ukázaly, že generování přesných zdůvodnění tímto způsobem může zlepšit výkonnost uvažování [10, 11], a přesně tento efekt vidíme v experimentech s CoT podněty. Konkrétně naučení LLM vypisovat relevantní myšlenkový řetězec, který vysvětluje jeho konečnou odpověď, může výrazně zlepšit výkon v úlohách, jako je aritmetické, symbolické a rozumové uvažování; viz níže.
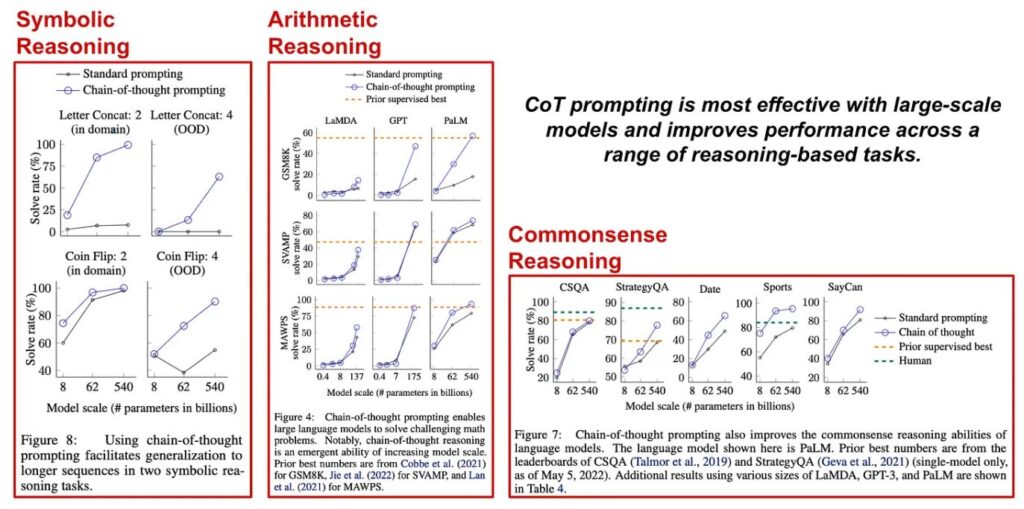
oblíbené varianty CoT. Kromě základní techniky CoT bylo zkoumáno několik variant této techniky, např.:
- Zero-shot CoT prompting: nahrazení všech příkladových zdůvodnění a místo toho vložení věty „Přemýšlejme krok za krokem“ na konec výzvy.
- Sebekonzistence: využití LLM k vytvoření více myšlenkových řetězců a přijetí většinového hlasování těchto více výstupů jako konečné odpovědi.
- Podněty od nejmenšího k největšímu: rozklad problémů uvažování na menší kroky, které se řeší postupně, přičemž výstup každého dílčího problému se použije jako vstup pro další.
Tyto techniky (znázorněné na obrázku níže) jsou podobné metodám CoT a přinášejí srovnatelné výsledky, ale každá z nich má jedinečné výhody. Například nulový CoT prompting je neuvěřitelně jednoduchý! Stačí, když do výzvy vložíme jediné tvrzení, místo abychom ručně psali nebo kurzírovali několik relevantních příkladů myšlenkového řetězce. Na druhou stranu je prompting typu least-to-most o něco složitější než vanilla CoT prompting, ale tato technika je také schopnější řešit problémy s uvažováním, které vyžadují mnoho kroků. Podněty typu least-to-most tak můžeme použít k řešení nejobtížnějších úloh, v nichž podněty typu CoT selhávají.

Z těchto technik je mou nejoblíbenější sebekonzistence. Proč? Protože je to jednoduchá technika, která je široce použitelná a velmi účinná. Ve skutečnosti tato myšlenka ani není specifická pro podněty CoT! Sebekonzistence může v mnoha případech zlepšit výkonnost aplikací LLM. Namísto generování jediného výstupu pomocí našeho LLM generujeme více výstupů a jejich průměr bereme jako konečnou odpověď, čímž zvyšujeme spolehlivost a přesnost.
Tato myšlenka mi připomíná modelové ansámbly v hlubokém učení, kdy i) nezávisle na sobě trénujeme několik modelů k řešení nějaké úlohy a ii) v době inference bereme průměr výstupů každého modelu. Ačkoli sebekonzistence používá pouze jeden model namísto ansámblu, podobné techniky byly použity v širší literatuře o hlubokém učení; např. pro simulaci ansámblu lze vygenerovat a zprůměrovat několik výstupů z neuronových sítí, které obsahují nedeterministické moduly, jako je dropout.
Rozšíření výzvy CoT.
Není jasné, jestli CoT podněty skutečně učí žáky se SVP „rozumně uvažovat“, nebo ne. Nicméně CoT prompting má značný praktický význam, protože jej lze použít k řešení složitých, vícekrokových problémů s LLM. Proto byla v poslední době zkoumána celá řada zajímavých myšlenek týkajících se podnětů CoT. V [16] je zkoumána multimodální verze CoT promptingu, v níž se k provádění různých argumentačních úloh používají obrazové i textové modality; viz níže.
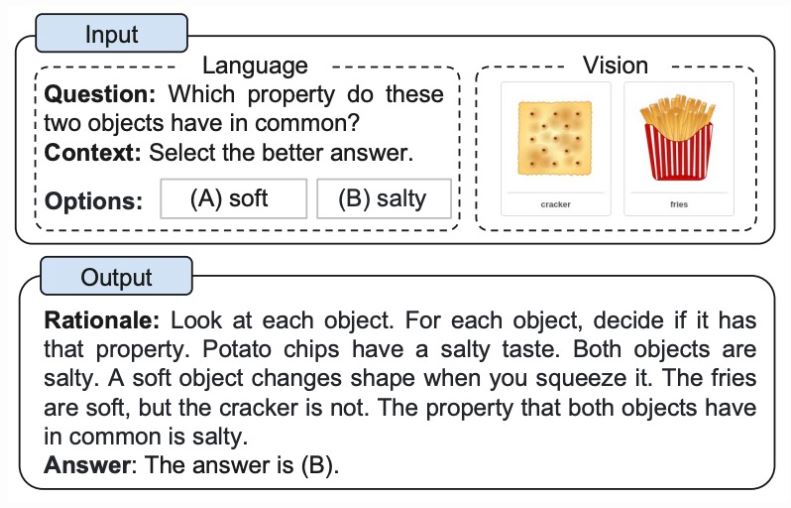
Kromě zkoumání více modalit dat (tj. obrázků a textu) autoři v mírně upravují nastavení CoT tím, že považují vícekrokové generování zdůvodnění a vyvozování odpovědí za dva odlišné kroky při řešení úlohy založené na uvažování; viz níže.

Jasným vyčleněním těchto složek můžeme snáze analyzovat zdroje chyb v podnětech CoT. Výsledkem je zjištění autorů v [16], že i) nesprávné odpovědi mohou být často způsobeny halucinacemi ve vygenerovaném zdůvodnění a ii) použití multimodálních dat vede ke generování efektivnějších zdůvodnění.

Autoři kombinují podněty CoT s myšlenkou aktivního učení (tj. použití samotného modelu k identifikaci dat, která by měla být zahrnuta do trénovací množiny). LLM nejprve odpovídá na několik otázek pomocí CoT promptingu. Odtud se výstupní „nejistota“ (měřená na základě neshod mezi více odpověďmi generovanými stejným LLM) používá k identifikaci otázek, kterým model špatně rozumí. Otázky v této skupině jsou pak ručně (lidmi) anotovány se správným myšlenkovým řetězcem a použity jako příklady pro řešení budoucích otázek.
Jedním z největších problémů, s nimiž se můžeme setkat při aplikaci CoT promptingu v praxi, je nedostatek několika málo příkladů, které by dobře odpovídaly úloze, kterou se snažíme vyřešit. Možná máme přístup k několika kvalitním myšlenkovým řetězcům, které můžeme zahrnout do našeho podnětu, ale co uděláme, když se problém, který se snažíme vyřešit, mírně liší od problému řešeného v těchto příkladech? Ačkoli takový problém může vést ke zhoršení výkonu, přístup navržený se snaží s tímto problémem bojovat. Konkrétně můžeme pomocí aktivního učení dynamicky rozpoznat, kdy jsou dostupné příklady pro výzvu CoT pro řešení určitého problému nedostatečné.
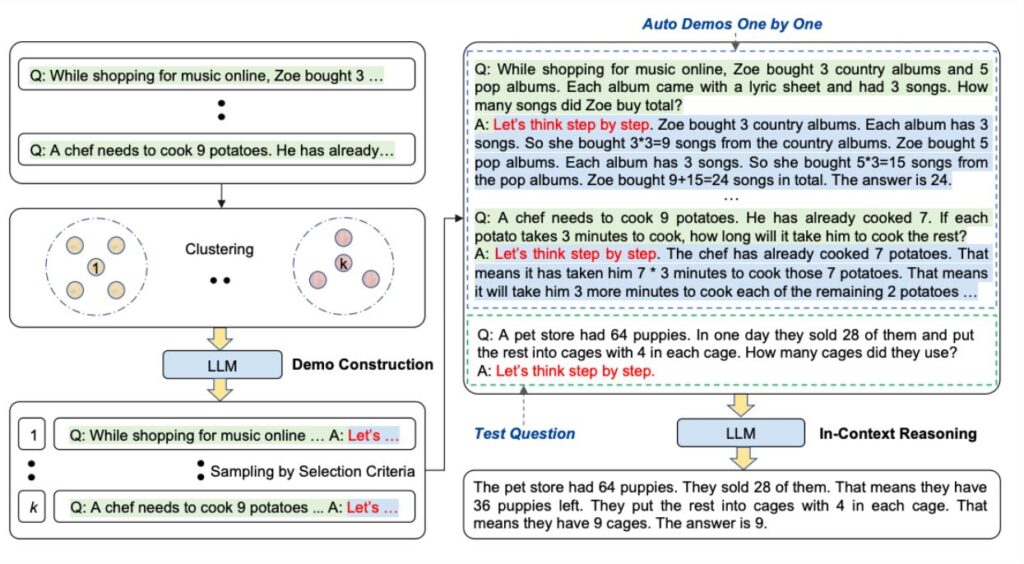
Automatic Chain-of-Thought (Auto-CoT)
Při použití myšlenkového řetězce s ukázkami je třeba ručně vytvářet účinné a rozmanité příklady. Tato ruční práce může vést k neoptimálním řešením. Zhang et al. (2022) navrhují přístup k eliminaci ručního úsilí využitím LLM s výzvou „Přemýšlejme krok za krokem“ k postupnému generování řetězců uvažování pro demonstrace. Tento automatický proces může přesto skončit chybami ve vygenerovaných řetězcích. Pro zmírnění dopadů chyb je důležitá různorodost demonstrací. Tato práce navrhuje Auto-CoT, který vzorkuje otázky s různorodostí a generuje argumentační řetězce pro konstrukci demonstrací.
Auto-CoT se skládá ze dvou hlavních fází:
- Fáze 1: shlukování otázek: rozdělení otázek daného souboru dat do několika shluků.
- Fáze 2: vzorkování demonstrací: výběr reprezentativní otázky z každého shluku a
generování jejího argumentačního řetězce pomocí Zero-Shot-CoT s jednoduchou heuristikou.
Jednoduchými heuristikami mohou být délka otázek (např. 60 tokenů) a počet kroků v odůvodnění (např. 5 kroků odůvodnění). To podněcuje model k používání jednoduchých a přesných demonstrací.
Postup je znázorněn níže (zdroj):
- Kódy de pro Auto-CoT isou zde.
Chain-of-thought prompting & Self-consistency
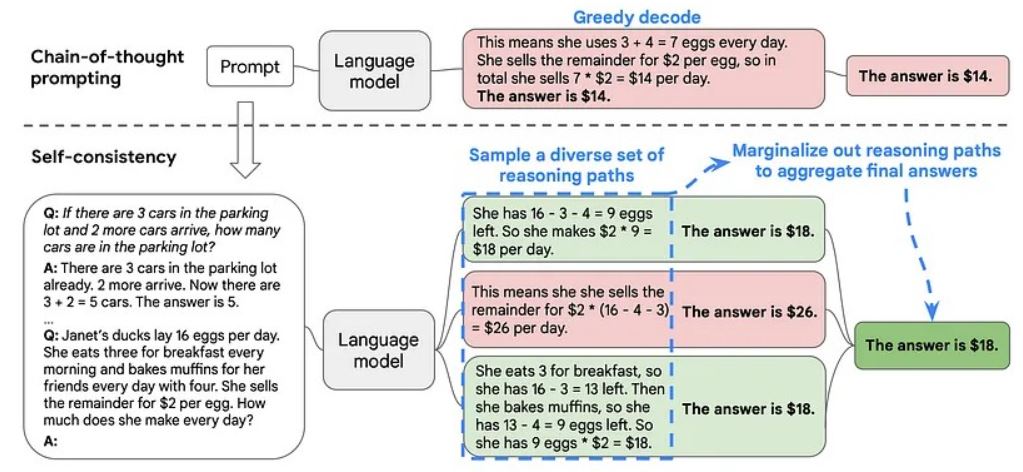
Q: Jsou-li na parkovišti 3 auta a přijedou další 2 auta, kolik aut je na parkovišti?“ s odpovědí „A: Na parkovišti už jsou 3 auta, přijedou 2 další. Nyní je tam 3 + 2 = 5 aut. Odpověď je 5.
Q: Kačeny Janet snášejí 16 vajec denně. Každé ráno sní tři k snídani a každý den peče muffiny pro své přátele se čtyřmi vejci. Zbytek prodává za 2 dolary za vejce. Kolik vydělá každý den?
A: