ChatGPT Rámce pro tvorbu promptů


Rozšíření na ukrajinský trh vedlo k vytvoření specializovaného AI asistenta pro překlad odborné terminologie a textů pro firemní web. Ukázalo cestu k efektivnímu překonání jazykových bariér při současném zachování SEO hodnoty a odborné přesnosti.
Společnost poskytující servis a opravy vývěv měla ambiciózní plán rozšířit své služby na Ukrajinu. Stávající web byl plný odborné terminologie a technických specifikací, které vyžadovaly precizní překlad. Klasické překlady od překladatelských agentur by stály desítky tisíc korun a mohly trvat týdny, navíc bez záruky správného SEO nastavení.
Rozhodli jsme se otestovat možnosti AI asistentů pro odborný překlad a lokalizaci obsahu. Cílem bylo vytvořit systém, který nejen přeloží, ale také optimalizuje obsah pro ukrajinské vyhledávače a místní trh.
Hlavním problémem byla potřeba překlenout jazykovou bariéru při zachování technické přesnosti a SEO síly. Standardní překladače selhávaly u odborné terminologie a nevěděly, jak přizpůsobit obsah místnímu trhu a vyhledávacím návykům.
Vytvořili jsme specializovaného AI asistenta „Překladač do ukrajinštiny“, který kombinuje odborný slovník s analýzou klíčových slov pro ukrajinský trh. AI ssistent nejen překládá, ale také zkoumá místní terminologii a optimalizuje pro ukrajinské SEO.
Proces konfigurace AI asistenta probíhal systematicky podle našeho standardního postupu. Kompletní metodiku konfigurace AI asistentů najdete v sekci „Konfigurace AI asistentů„, kde podrobně vysvětlujeme všechny kroky od návrhu funkcí přes technické nastavení až po ladění a správu.
Ukrajinská verze webu začala organicky růst ve výsledcích Yandex a Google.ua díky přesné lokalizaci klíčových slov. Online PR články s odbornými překlady získaly kvalitní zpětné odkazy z ukrajinských odborných portálů.
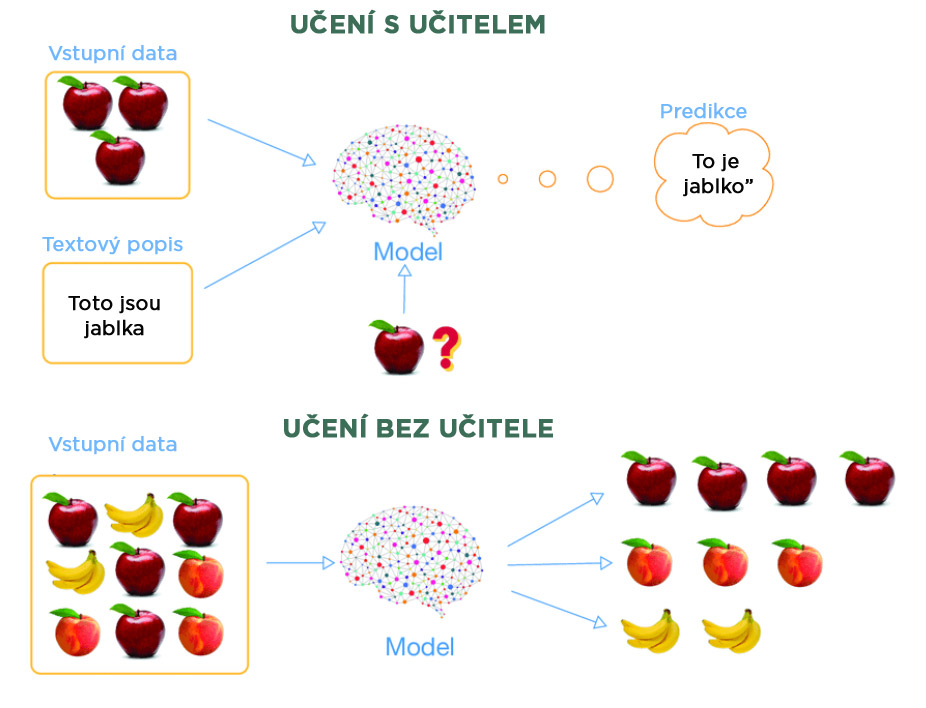
Učení s učitelem (supervised learning) zahrnuje trénovací sadu, která obsahuje označená data, a cílem je najít mapovací funkci, která převádí vstupy na požadované výstupy.
Například model dostane datovou sadu – řekněme ovoce. Shromáždí všechny informace, jako je tvar, velikost, chuť a název ovoce, a učí se z každého typu dat. Jakmile je model vytrénován, je mu předložen nový druh ovoce (testovací data) a na základě trénovacích dat model předpoví název ovoce podle analýzy všech dříve naučených informací.
Učení bez učitele (unsupervised learning) na rozdíl od toho vykazuje samoorganizaci. Algoritmus pracuje s neoznačenými a neklasifikovanými daty a jeho úkolem je v nich najít skryté vlastnosti nebo struktury. Zahrnuje například seskupování dat do skupin (klastrů) na základě podobností, vzorců nebo rozdílů bez jakéhokoli předchozího vedení.
Například model dostane neoznačená data obrázků koček a psů. Model data rozdělí do dvou různých klastrů, aniž by znal jejich označení. Když je mu následně předložen nový obrázek kočky (testovací data), na základě získaných znalostí jej zařadí do klastru koček.
Učení s učitelem je třída metod strojového učení, která stojí v opozici proti učení bez učitele. Trénovací data se přitom sestávají ze vstupních objektů (vektorů jejich příznaků) a jejich požadovaných výstupních ohodnocení, tj. závisle proměnných (obecně také ve tvaru vektorů), tj. výroků učitele o objektu.
Výstupem naučené funkce (jejíž příklady jsou obsaženy v trénovacích datech) pak mohou být spojité hodnoty (při regresi) anebo binární hodnoty označující příslušnost vstupních objektů do daných tříd (při klasifikaci). Naučená funkce pak dokáže odhadovat výstupní ohodnocení každého vstupního objektu (i neobsaženého v trénovacích datech) poté, co zpracuje trénovací příklady (tj. dvojice vstup a požadovaný výstup). Aby to dokázala, musí umět zobecnit (generalizovat) souvislost mezi vstupy a výstupy danou příklady obsaženými v trénovacích datech „smysluplným“ způsobem.[1] (Porovnejte s učením bez učitele.)
Přeučení
Overfitting neboli přeučení je stav, kdy je systém příliš přizpůsoben množině trénovacích dat, ale nemá schopnost generalizace a selhává na validační množině dat. To se může stát např. při malém rozsahu trénovací množiny nebo pokud je systém příliš komplexní, např. příliš mnoho skrytých neuronů v neuronové síti. Řešením je zvětšení trénovací množiny, snížení složitosti systému nebo různé techniky regularizace, jako je zavedení náhodného šumu (což v zásadě odpovídá rozšíření trénovací množiny), zavedení omezení na parametry systému, které v důsledku snižuje složitost popisu naučené funkce, nebo předčasné ukončení učení (průběžné sledování chyby na validační množině a konec učení ve chvíli, kdy se chyba na této množině dostane do svého minima).
Trénovací data
Trénovací data jsou data (v konkrétní počítačové podobě například databáze nebo adresář se soubory), na kterých se v umělé inteligenci nebo strojovém učení odhadují parametry a/nebo struktura modelu. Trénovací data se skládají ze vstupního vektoru (množiny) dat a v případě učení s učitelem také odpovídajícího výstupního vektoru dat.
Pro správné naučení inteligentního systému je obvykle potřeba dostatečně reprezentativní množství trénovacích dat. Inteligentní systémy jsou v podstatě funkce, které ze vstupního vektoru vypočítají výstupní vektor a podle rozdílu od správného výstupního vektoru upraví své vnitřní parametry. Tento proces se opakuje, dokud není systém dostatečně naučen. Trénovací data se dle způsobu užití dělí do tří skupin:
Trénovací množina je sada dat, ve které algoritmus nachází určitý vztah, tj. provádí jejich (regresní analýzu), čímž se ‚učí‘.
Validační množina je sada dat, která se používají pro případnou úpravu parametrů učení ve snaze vyhnout se jeho ‚přeučení‘.
Testovací množina je sada dat, která se používají pro ověření kvality naučeného systému. Měla by být odlišná od trénovací resp. validační množiny. Systém je správně naučený tehdy, jestliže se shodnou úspěšností vyhodnocuje trénovací množinu i testovací množinu. Pokud má vyhodnocení trénovací množiny výrazně vyšší úspěšnost, je systém přeučený.
Reference
Maieutika je termín používaný samotným Sókratem pro umění vést dialog. Maieutika je součást sokratovské metody. Jejím jádrem je myšlenka, že pravda je latentně přítomna v rozumu každého člověka už od narození, ale musí se „přivést na svět“ skrz správně položené otázky učitele.
Technika maieutického nabádání je způsob, jak testovat konzistenci a integritu odpovědí poskytnutých jazykovým modelem na logické nebo faktické otázky.
Cílem je zajistit, že odpovědi nejen znějí pravděpodobně, ale že jsou také logicky konzistentní.
V příkladu na obrázku, je zadán výrok „Válka nemůže mít remízu“ a model poskytuje odpověď.
Maieutický strom je vytvořen tak, že se rozvíjí možné argumenty pro a proti této odpovědi, které jsou pak systematicky ověřovány. Každá cesta stromu končí, až když narazí na logicky konzistentní závěr.
V podstatě, po počáteční odpovědi modelu se ptáme další otázky, abychom ověřili, zda model může konzistentně odůvodnit svou odpověď. Pokud model poskytne protichůdné zdůvodnění, jeho původní odpověď nemůže být považována za důvěryhodnou.
Vážení návrhů a vztahů a použití Max-SAT řešiče pak pomáhá určit, která cesta v maieutickém stromu je nejvíce pravděpodobná nebo nejsprávnější, a tím poskytuje konečnou predikci pro původní výrok. V tomto příkladu byl konečný závěr, že výrok „Válka nemůže mít remízu“ je nepravdivý.
Je to tedy způsob, jak posoudit, zda jsou odpovědi jazykového modelu nejen relevantní, ale i vzájemně konzistentní a logicky validní.
Technika AMA („Ask Me Anything“) prompt engineeringu je metoda pro vylepšení interakce s jazykovými modely, jako je GPT. Cílem je zlepšit schopnost modelu odpovídat na otázky založené na kontextu a ověřovat tvrzení.
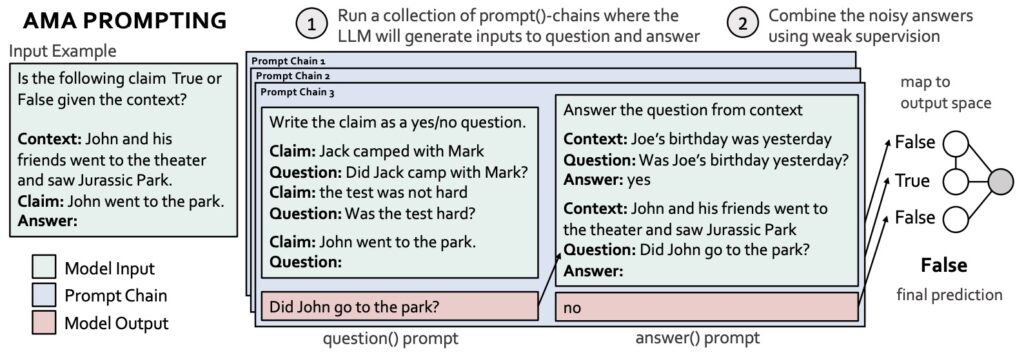
Zde si vysvětlíme techniku AMA (Ask Me Anything) prompt engineeringu, která je využívána k ověřování tvrzení na základě kontextu pomocí jazykových modelů. Tato technika využívá dvou typů promptů: question() prompt, který převádí tvrzení do formy otázky typu ano/ne, a answer() prompt, který zodpovídá tuto otázku na základě poskytnutého kontextu. Kombinace odpovědí pomocí metody slabého dohledu (weak supervision) pak umožňuje určit, zda je původní tvrzení pravdivé nebo nepravdivé. Tento postup si podrobně popíšeme ve dvou hlavních krocích, jak je znázorněno na obrázku.
Technika, známá jako „AI řetězy“ nebo „AI Chaining“, je přístup v prompt engineeringu, který umožňuje rozložit komplexní úkol na několik menších, jednodušších částí. AI se poté postupně vypořádává s každým menším úkolem a využívá výsledky předchozích úkolů k dalšímu postupu. Tímto způsobem může AI efektivněji zpracovat a reagovat na složitější dotazy nebo úkoly.
Generated Knowledge Prompting je technika, kde model nejprve vygeneruje relevantní znalosti nebo fakta k danému tématu – a teprve poté, obohacen o tyto znalosti, odpoví na původní otázku.
Standardní přístup:
„Je tučňák savec?“ → model rovnou odpoví.
Generated Knowledge přístup:
Model nejprve vygeneruje znalosti → „Tučňáci jsou ptáci, kteří nemohou létat. Savci jsou teplokrevní živočichové, kteří kojí mláďata. Tučňáci kladou vejce…“ → a teprve na základě těchto vygenerovaných faktů formuluje finální odpověď.

Diagram ukazuje dva provázané kroky:
Spodní část – generování znalostí: Do modelu (PLM – Pre-trained Language Model) vstoupí výzva složená ze tří složek: instrukce (jak má model znalosti generovat), ukázky (few-shot příklady) a samotná otázka. Model na základě toho vygeneruje několik znalostních výroků – Znalost 1, Znalost 2 atd.
Horní část – integrace a odpověď: Původní otázka spolu s vygenerovanými znalostmi vstoupí do fáze integrace, která z nich sestaví finální odpověď.
Klíčové je, že znalosti nevkládá člověk zvenčí – generuje je sám model ještě před tím, než odpoví. A proto je to právě Generated Knowledge Prompting, nikoli jen přidávání kontextu do promptu, jak bylo v předchozím příkladu s cihlami.
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Generativní AI dokáže bleskově procházet velké objemy zdrojů, vyhledat relevantní data a vrátit je ve srozumitelném souhrnu. Ušetří tak hodiny manuálního vyhledávání a pomůže odhalit i skrytá spojení mezi informacemi.
Příklady praktických promptů:
1. Rychlý research konkurence:
Vyhledej všechny klíčové informace o firmě [název konkurenta]
z veřejně dostupných zdrojů a shrň jejich hlavní produkty,
cílovou skupinu, cenovou politiku a nedávné novinky.
Výsledek strukturuj do přehledné tabulky.2. Analýza trendů v oboru:
Projdi poslední zprávy a články o [téma/technologie] z posledních
6 měsíců a identifikuj 5 hlavních trendů. U každého trendu uveď
konkrétní příklady a zdroje.Pro efektivní využití AI ve výzkumu konkurence doporučujeme naši službu výzkum konkurence, která kombinuje automatizované nástroje s expertní analýzou.
Modely LLM umí syntetizovat akademické studie, zprávy či interní dokumenty a vytvářet z nich přehledné analýzy, grafy i doporučení. Dokážou odhalit vzorce, trendy a slabá místa, která by lidskému týmu snadno unikla.
Příklady analytických promptů:
1. Analýza zákaznických recenzí:
Analyzuj přiložených 200 zákaznických recenzí a identifikuj:
- 5 nejčastějších pochval
- 5 nejčastějších stížností
- Skrytá témata, která se opakují
- Doporučení pro zlepšení produktu
Výsledky zobraz v grafech a tabulkách.2. Komparativní studie řešení:
Porovnej 3 různé přístupy k [problém/úkol] na základě kritérií:
náklady, časová náročnost, efektivita, rizika. Vytvoř bodové
hodnocení a doporuč nejlepší řešení s odůvodněním.Pro pokročilé analytické úkoly nabízíme prediktivní analýzu, která využívá AI k předpovídání budoucího vývoje na základě historických dat.
AI vytáhne konkrétní fakta, čísla nebo klíčové fráze z nestrukturovaných textů, e‑mailů či skenů. Výsledkem je čistá tabulka nebo databáze připravená k dalšímu zpracování a automatizaci procesů.
Příklady extrakčních promptů:
1. Získání kontaktů z dokumentů:
Z přiloženého PDF dokumentu vytáhni všechny:
- Jména osob a jejich role
- E-mailové adresy
- Telefonní čísla
- Adresy firem
Výsledek vrať jako CSV tabulku.2. Extrakce klíčových metrik:
Projdi tento obchodní report a vytvoř strukturovaný přehled
obsahující: měsíční tržby, počet nových zákazníků, průměrnou
hodnotu objednávky, konverzní poměr. Zobraz data v časové řadě.Pro automatizaci extrakce dat z webů využijte automatizaci s Make.com, která dokáže pravidelně sbírat a zpracovávat data bez manuálního zásahu.
Generativní AI umí zasadit fakta do kontextu, vysvětlit historické souvislosti a předložit ucelený příběh. Vhodně kombinuje chronologii, kauzalitu i relevantní citace, čímž zjednoduší pochopení složitých událostí.
Příklady interpretačních promptů:
1. Kontextualizace událostí:
Vysvětli vliv [historická událost] na [současný stav/trend]
v kontextu [obor/region]. Zahrň klíčové milníky, hlavní aktéry
a dlouhodobé důsledky. Použij timeline formát.2. Analýza kauzality:
Na základě poskytnutých dat vysvětli příčinné souvislosti mezi
[událost A] a [událost B]. Identifikuj přímé i nepřímé faktory
a ohodnoť jejich vliv na stupnici 1-10.Pro hlubší pochopení dat doporučujeme analýzu sentimentu, která odhaluje emocionální podtext v textech a pomáhá lépe interpretovat názory zákazníků.
Díky strojovému učení lze dokumenty, obrázky či produkty automaticky přiřazovat do správných kategorií. AI se přizpůsobí firemní taxonomii a zlepšuje přesnost s každým dalším příkladem.
Příklady klasifikačních promptů:
1. Třídění dokumentů:
Zkategorizuj následující dokumenty do skupin: faktury, smlouvy,
objednávky, reklamace, ostatní. Pro každou kategorii uveď
stručný důvod zařazení a úroveň jistoty (%).2. Segmentace zákazníků:
Na základě těchto zákaznických dat (věk, nákupní historie,
hodnota košíku, frekvence nákupů) vytvoř 4-5 zákaznických
segmentů. Každý segment pojmenuj a popiš jeho charakteristiky.Efektivní segmentaci trhu využívá naše služba segmentace trhu, která kombinuje AI analýzu s marketingovým know-how pro přesné zacílení kampaní.
Modely zvládají vícejazyčné překlady, ale i úpravy tónu, stylu či formátu textu. Umí tak rychle vytvořit lokalizované materiály nebo převést neformální zápisky do profesionálního stylu.
Příklady transformačních promptů:
1. Lokalizace obsahu:
Přelož následující marketingový text do němčiny a přizpůsob ho
německému trhu - použij formální tón, lokální reference a upravit
příklady tak, aby rezonovaly s německými zákazníky.2. Změna stylu dokumentu:
Převeď tyto neformální poznámky z meetingu do profesionálního
formátu business reportu. Zachovej všechny klíčové informace,
ale uprav jazyk, strukturu a přidej executive summary.Pro kvalitní překlady doporučujeme využít nástroj AI překladač, který kombinuje strojové učení s kontextovým porozuměním pro přesné překlady.
Generativní AI navrhuje funkce, generuje celé bloky kódu a pomáhá s laděním či refaktoringem. Umožňuje tak vývojářům soustředit se na architekturu a logiku místo repetitivního psaní stavebních kamenů.
Příklady programovacích promptů:
1. Generování API endpointu:
Vytvoř REST API endpoint v Python Flask pro registraci uživatele.
Endpoint by měl validovat email, hashovat heslo pomocí bcrypt,
ukládat do PostgreSQL databáze a vracet JWT token. Zahrň error handling.2. Refaktoring legacy kódu:
Refaktoruj tento JavaScript kód: [vložit kód]. Použij moderní
ES6+ syntaxi, rozděl do menších funkcí, přidej TypeScript typy
a navrhni unit testy. Vysvětli změny a důvody.Moderní přístup ke kódování s AI představuje vibe coding, který kombinuje lidskou kreativitu s výkonem AI pro rychlejší vývoj aplikací.
Automaticky odhalí gramatické chyby, zlepší stylistiku a sjednotí formát dokumentu podle vybraných pravidel. Výsledkem je profesionálně upravený text bez ručního pročítání.
Příklady korekturních promptů:
1. Komplexní revize textu:
Zkontroluj tento text a oprav: gramatické chyby, pravopisné chyby,
interpunkci, stylistiku. Zlepši čitelnost, odstraň redundance
a zajisti konzistentní formátování. Vrať upravený text s vysvětlením změn.2. Adaptace na cílovou skupinu:
Přepiš tento technický dokument pro netechnické publikum.
Zjednodušit jazyk, nahradit žargon běžnými výrazy, přidat příklady
z praxe a zajistit, aby byl text srozumitelný pro laiky.Pro profesionální zpracování marketingových textů využijte naši službu AI copywriting, která kombinuje AI technologie s expertním copywritingem.
AI umí analyzovat procesy, navrhnout zjednodušení a vytvořit detailní dokumentaci či návody. Zkracuje tak dobu zaškolení nováčků a zajišťuje konzistentní know‑how v týmu.
Příklady optimalizačních promptů:
1. Analýza pracovního procesu:
Analyzuj tento firemní proces: [popis procesu]. Identifikuj
úzká místa, nadbytečné kroky a navrhni optimalizace. Vytvoř
nový proces diagram s časovými úsporami a odhadovanými náklady implementace.2. Tvorba onboarding dokumentace:
Vytvoř kompletní onboarding dokumentaci pro nové vývojáře v našem týmu.
Zahrň: nastavení vývojového prostředí, přehled architektury,
coding standards, git workflow, deployment proces. Formát: krok za krokem.Pro vytváření konzistentní procesní dokumentace doporučujeme využít standardní operační postup, který zajistí jednotný přístup k dokumentaci napříč celou firmou.
Při brainstormingu dokáže AI generovat pestrou škálu originálních konceptů, sloganů či produktových funkcí. Inspiruje týmy k novým směrům, které by je samy nemusely napadnout.
Příklady kreativních promptů:
1. Brainstorming produktových funkcí:
Vygeneruj 20 inovativních funkcí pro mobilní aplikaci [typ aplikace].
Zaměř se na: zlepšení uživatelské zkušenosti, AI funkce,
gamifikaci, sociální prvky. U každé funkce uveď benefit a složitost implementace.2. Tvorba marketingových sloganů:
Vytvoř 15 reklamních sloganů pro [produkt/službu]. Slogany by měly být:
krátké (max 7 slov), zapamatovatelné, vtipné nebo emotivní,
zdůrazňovat hlavní benefit. Navrhni i 3 varianty pro různé cílové skupiny.Pro systematický přístup ke kreativnímu psaní využijte vzorce pro psaní přesvědčivých textů, které kombinují osvědčené principy s AI generováním.
Modely umí formulovat argumenty pro i proti, hodnotit rizika a přinášet různé perspektivy na dané téma. Usnadňují tak tvorbu expertních posudků, recenzí nebo rozhodovacích podkladů.
Příklady argumentačních promptů:
1. Vyvážená analýza rozhodnutí:
K rozhodnutí [popis situace] vytvoř analýzu pro/proti.
Pro každou stranu uveď 5 silných argumentů, ohodnoť rizika
a příležitosti, přidej reálné příklady a doporuč finální postoj
s odůvodněním.2. Multi-perspektivní pohled:
K tématu [téma] vytvoř názory z pohledu 4 různých stakeholderů:
zákazník, investor, zaměstnanec, konkurence. U každého pohledu
vysvětli jejich priority, obavy a očekávání.Pro strukturované uvažování a argumentaci využijte techniku Chain of Thought, která pomáhá AI generovat logicky provázané a zdůvodněné závěry.
AI dokáže napodobit reakce různých uživatelských person, zákazníků či aktérů v modelových situacích. Pomáhá testovat chatboty, marketingové kampaně i krizové scénáře bez nutnosti nákladných pilotů.
Příklady simulačních promptů:
1. Testování customer support scénářů:
Simuluj konverzaci mezi zákazníkem a support chatbotem. Zákazník:
rozhněvaný, technicky nezkušený, má problém s [produkt].
Chatbot by měl problém vyřešit do 5 zpráv. Vytvoř 3 různé verze konverzace.2. Persona-based marketing test:
Vytvoř 3 user persony pro [produkt/službu] a simuluj jejich reakci
na marketingovou kampaň [popis kampaně]. U každé persony uveď:
demografii, motivace, bolesti, pravděpodobnou reakci a konverzní potenciál.Praktické využití chatbotů pro různé scénáře popisuje článek role AI chatbota v sektoru vzdělávání, který ukazuje reálné příklady simulace interakcí.
Od krátkých příspěvků na sociální sítě až po rozsáhlé články – generativní AI vytvoří čtivý obsah na míru publiku i zadání. Výsledný text lze dále ladit, zkracovat či doplňovat o fakta.
Příklady textových promptů:
1. LinkedIn post s engagement:
Napiš LinkedIn příspěvek o [téma] pro [cílovou skupinu].
Post by měl: začínat hookem, být max 150 slov, obsahovat osobní zkušenost,
mít jasný CTA, používat hashtags. Tón: profesionální ale přátelský.2. SEO-optimalizovaný článek:
Vytvoř článek (1500 slov) o [téma]. Struktura: úvod s hooks,
5 H2 nadpisů, praktické příklady, bullet pointy, závěr s CTA.
Zahrň klíčová slova: [seznam KW]. Tón: expertní ale srozumitelný.Pro efektivní tvorbu AI promptů využijte kompletní přehled prompt engineering techniky, které maximalizují kvalitu generovaných textů.
Při znalosti šablony dokáže AI vyplnit všechny potřebné sekce, například smlouvy, e‑maily či reporty. Zajišťuje tak konzistenci a zkracuje čas potřebný na přípravu rutinních dokumentů.
Příklady šablonových promptů:
1. Generování obchodního emailu:
Použij tuto šablonu follow-up emailu: [šablona].
Vyplň pro klienta [jméno firmy], který projevil zájem o [produkt].
Zahrň: personalizovaný úvod, rekapitulaci meetingu, next steps,
deadline. Tón: profesionální ale ne agresivní.2. Měsíční reportovací template:
Vytvoř měsíční report podle této struktury: [struktura].
Data: [klíčové metriky]. Report by měl obsahovat: executive summary,
grafy trendů, porovnání s minulým měsícem, doporučení pro další období.Systematický přístup k práci se šablonami nabízí technika template-based prompting, která zajišťuje konzistentní a kvalitní výstupy.
Modely predikují nejpravděpodobnější pokračování textu, kódu nebo dialogu a umožňují rychlé autocomplety. V oblasti dat navíc odhadují budoucí trendy či chování na základě historických vzorců.
Příklady prediktivních promptů:
1. Predikce tržních trendů:
Na základě těchto historických dat [data] předpověz vývoj [metriky]
pro příštích 6 měsíců. Zahrň: očekávaný trend, seasonality,
rizikové faktory, confidence interval. Vizualizuj ve formátu grafu.2. Dokončení code snippetu:
Dokonči tuto funkci: [neúplný kód]. Funkce by měla [popis funkcionality].
Použij best practices, přidej error handling, docstring a navrhni
2-3 unit testy. Vysvětli logiku implementace.Pro pokročilé prediktivní úlohy doporučujeme techniku retrieval augmented generation, která kombinuje AI model s externími znalostními bázemi pro přesnější předpovědi.
Odpovědi na nejčastější dotazy ohledně praktického nasazení AI nástrojů v různých oblastech
Generativní AI najde uplatnění v automatizaci výzkumu konkurence, analýze zákaznických dat, tvorbě marketingových textů a personalizaci obsahu.
Kvalita AI textů závisí na kvalitě promptu a kontextu. Moderní modely vytváří profesionální texty srovnatelné s lidským psaním, vyžadují ale často úpravu pro specifickou značku nebo tón.
Nejlepších výsledků dosáhnete kombinací AI generování s lidskou revizí a využitím prompt engineering technik.
AI je mocný pomocník, ale ne náhrada za programátory. Dokáže generovat kód, pomáhat s debuggingem a refaktoringem, ale potřebuje lidského experta pro architekturu, strategická rozhodnutí a komplexní problematiku.
| Oblast | AI dokáže | AI nedokáže |
|---|---|---|
| Generování kódu | Rutinní funkce, snippety | Komplexní architektura |
| Debugging | Základní chyby, syntaxe | Logické chyby v kontextu |
| Dokumentace | Technické popisy | Strategické rozhodnutí |
Zvyšuje produktivitu vývojářů, nenahrazuje je. Více o moderním přístupu ke kódování najdete v článku o vibe coding.
Přesnost AI predikcí závisí na kvalitě a množství historických dat. Pro krátkodobé predikce s dostatečnými daty dosahuje AI vysoké přesnosti (80-95%). Dlouhodobé předpovědi nebo situace s omezenými daty jsou méně spolehlivé (60-75%).
Vždy doporučujeme kombinovat AI analýzu s lidskou expertízou. Pro pokročilé predikce využijte naši službu prediktivní analýzy.
Prompt je strukturovaná instrukce, která zahrnuje kontext, roli, specifický úkol a očekávaný formát výstupu. Běžná instrukce je jednoduchý příkaz bez kontextu.
| Parametr | Běžná instrukce | Kvalitní prompt |
|---|---|---|
| Délka | 1-2 věty | 5-15 vět |
| Kontext | Žádný nebo minimální | Detailní popis situace |
| Formát výstupu | Neurčený | Přesně specifikovaný |
| Kvalita výsledku | Variabilní | Konzistentně vysoká |
Kvalitní prompt vede k výrazně lepším a relevantnějším výsledkům díky přesnému nastavení parametrů a očekávání. Naučte se tvořit efektivní prompty v našem průvodci prompt engineering pro začátečníky.
DERA (Dialog-Enabled Resolving Agents) je technika, kde místo jednoho AI modelu spolupracují dva agenti – každý s jinou rolí – a vzájemným dialogem dospějí k lepšímu výsledku, než by dosáhl kterýkoli z nich sám.
Funguje to takto: první agent, Decider (Rozhodovatel), vygeneruje první verzi odpovědi. Druhý agent, Researcher (Výzkumník), si tuto odpověď přečte, kriticky ji posoudí a upozorní na to, co chybí, co by mohlo být nepřesné nebo co stojí za hlubší prozkoumání. Decider pak tyto podněty vyhodnotí, relevantní zapracuje a vytvoří lepší, doplněnou verzi. Tento dialog může proběhnout víckrát, dokud není výsledek dostatečně dobrý.
Klíčový je rozdíl v rolích: Researcher hledá problémy a navrhuje, Decider má poslední slovo a rozhoduje, co skutečně zapracuje do finálního výstupu.
Technika vznikla primárně pro oblast zdravotnictví – tedy prostředí, kde nepřesná nebo neúplná odpověď může mít vážné následky. Výsledky byly působivé: lékaři v hodnocení preferovali DERA výstupy oproti standardním GPT-4 odpovědím v 90 % případů u shrnutí lékařských rozhovorů a v 84 % u tvorby plánů péče o pacienta.
Zjednodušeně řečeno: DERA je jako mít dva kolegy, kteří si navzájem kontrolují práci – jeden píše, druhý kritizuje, a výsledek je výrazně lepší, než kdyby pracoval každý sám.
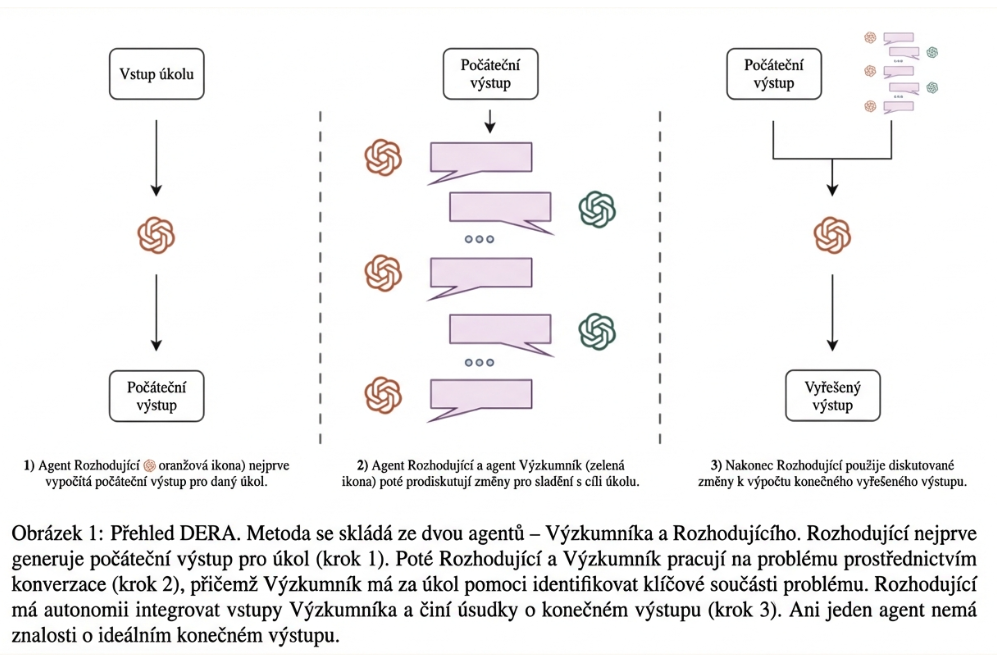
Zdroj: DERA: Enhancing Large Language Model Completions with Dialog-Enabled Resolving Agents (autoři Varun Nair, Elliot Schumacher, Geoffrey J. Tso, Anitha Kannan). ze dne [ 30. března 2023 ].

✓ Žádost odeslána!
Ozveme se vám do 24 hodin s potvrzením termínu.