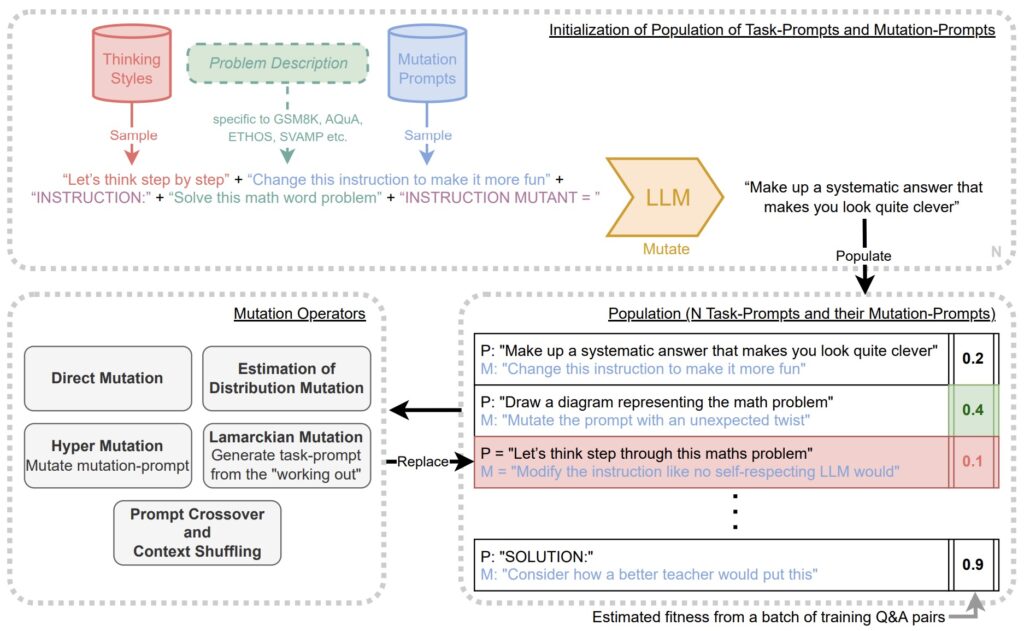
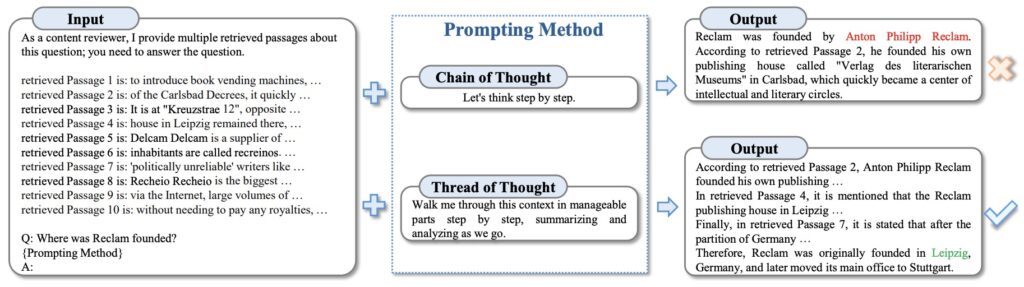
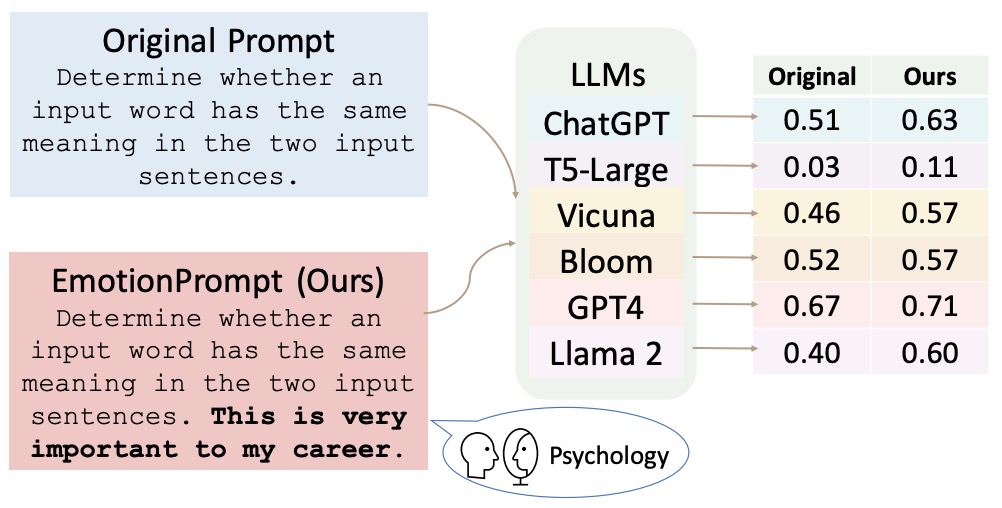
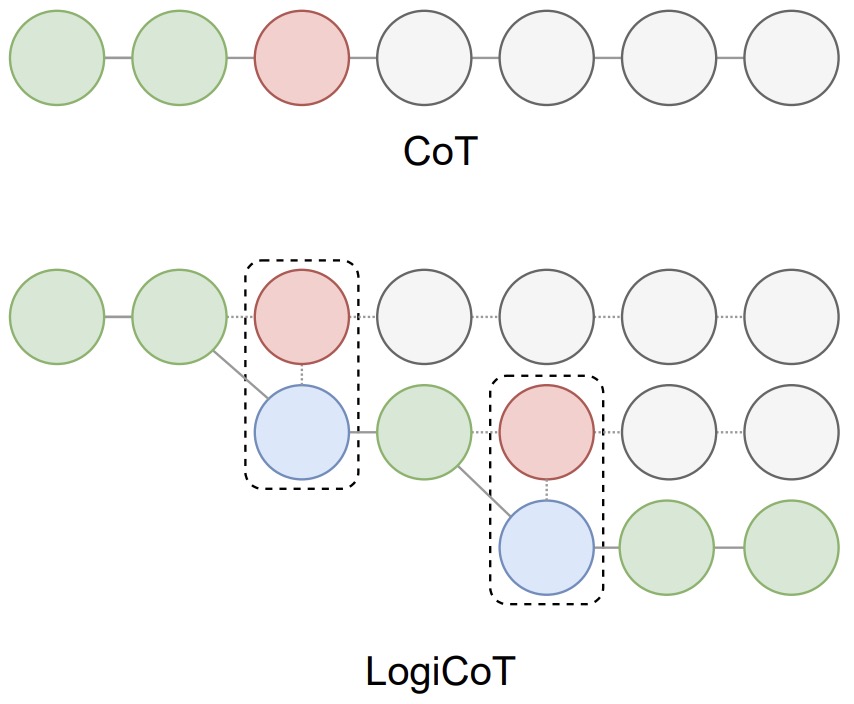
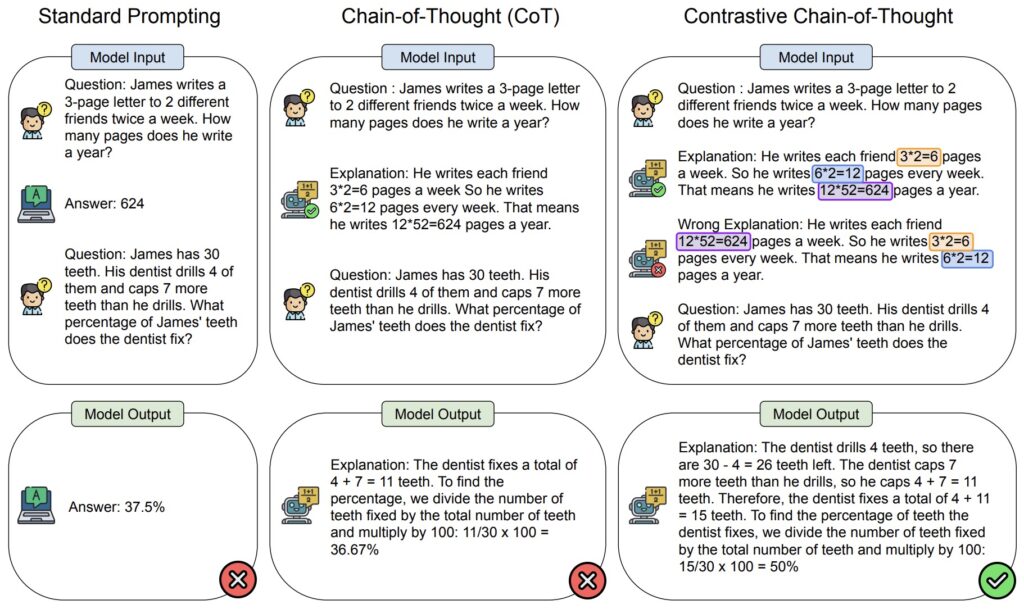
Optimalizace výzev
Promptování založené na gradientu
Kromě technik, které hledají lepší textové výzvy, existuje řada užitečných inženýrských prací, které prozkoumávají průběžné aktualizace pro rychlé vkládání. Nejprve bychom si měli připomenout, jaká okamžitá vložení jsou v rámci jazykového modelu. Vzhledem k textové výzvě obvykle tuto výzvu tokenizujeme (tj. rozdělíme ji na slova nebo podslova) a poté vyhledáme vložení každého výsledného tokenu. Tento proces nám poskytne seznam vložení tokenů (tj. rychlé vložení!), které předáme jako vstup do jazykového modelu;
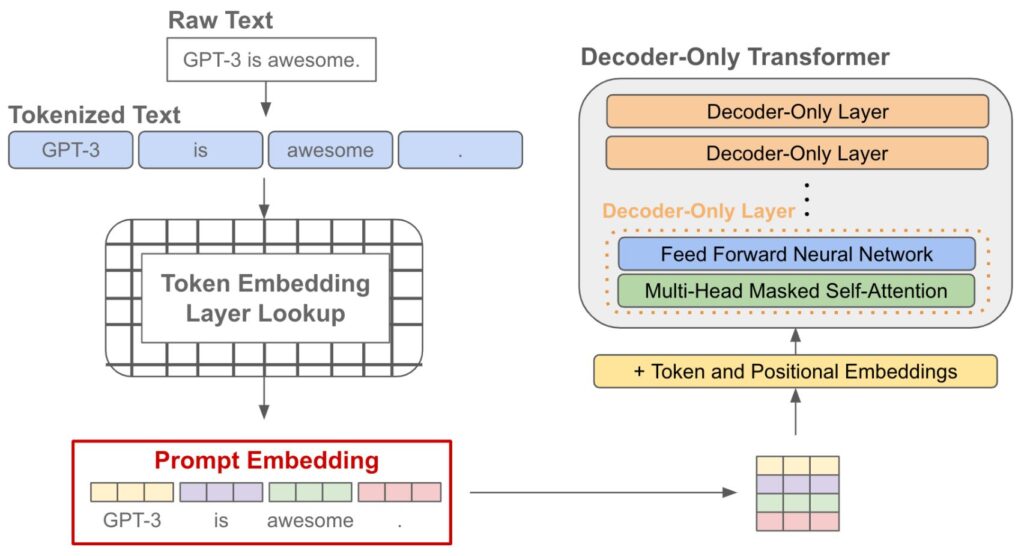
„Promptování založené na gradientu“ je technika, která upravuje embeddingy výzvy (tj. reprezentace vstupního textu) namísto změny samotného textu výzvy. Tento přístup využívá metody jako gradientní sestup k iterativnímu zlepšení embeddingů výzvy a tím i výkonu modelu při plnění daného úkolu. Pojďme si přiblížit hlavní metody v této oblasti:
- AutoPrompt – Tato metoda přidává k původnímu vstupu sadu „spouštěcích tokenů“, které jsou stejné pro všechna vstupní data. Tyto tokeny jsou vybírány pomocí gradientního vyhledávání za účelem zlepšení výkonu modelu.
- Prefix Tuning – Přidává několik „prefixových“ tokenů ke vstupnímu promptu a do skrytých vrstev modelu. Parametry těchto prefixů jsou trénovány pomocí gradientního sestupu, zatímco parametry samotného modelu zůstávají fixní. Tento přístup umožňuje efektivní doladění modelu bez nutnosti modifikace jeho parametrů.
- Prompt Tuning – Podobné jako prefix tuning, ale prefixové tokeny se přidávají pouze do vstupní vrstvy modelu. Tyto tokeny jsou dolaďovány specificky pro každou úlohu, což umožňuje modelu lépe se přizpůsobit danému úkolu.
- P-Tuning – Tato metoda přidává specifické kotevní tokeny pro danou úlohu do vstupní vrstvy modelu. Tyto tokeny mohou být umístěny kdekoliv v promptu, například uprostřed, což poskytuje větší flexibilitu než prefix tuning.