Sequential prompting (sekvenční promptování) je technika prompt engineeringu, kdy místo jednoho velkého promptu používáš sérii promptů v určitém pořadí. Každý krok má jasný dílčí cíl (např. analýza → návrh → kontrola → finální výstup) a postupně model „vedeš“ k lepšímu výsledku. Smysl je rozdělit složitý úkol na menší části, které se dají snadněji řídit a kontrolovat.
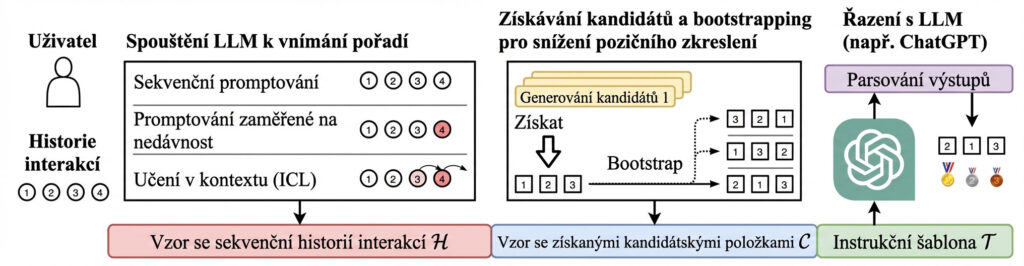
Tato infografika ukazuje jednoduchý postup, jak využít historii uživatelských interakcí a jazykový model (LLM)
k tomu, aby systém uměl vybrat a seřadit nejrelevantnější položky (nebo odpovědi). Celé je to rozdělené do čtyř
logických bloků zleva doprava.
1) Levý blok: Uživatel + historie interakcí (1–4)
Vlevo je uživatel a pod ním historie interakcí. Kroužky 1, 2, 3, 4
představují události v čase:
- 1 = nejstarší interakce
- 4 = nejnovější interakce
Pointa: u spousty úloh není důležité jen co uživatel dělal, ale také v jakém pořadí a co je „čerstvé“.
2) Blok „Spouštění LLM k vnímání pořadí“
Tento blok ukazuje tři způsoby, jak modelu předat historii tak, aby pochopil časovou posloupnost a váhu jednotlivých kroků:
A) Sekvenční promptování
Historii předáš modelu chronologicky (1 → 2 → 3 → 4). Model pak „vidí příběh“ tak, jak se stal, a snáz pochopí vývoj
záměru nebo preferencí.
B) Promptování zaměřené na nedávnost
Tady dáváš důraz na to, že poslední kroky (např. 4) jsou důležitější než starší. Často se to dělá tak, že se novější věci
zvýrazní, přidá se váhování („nejvíc ber v potaz poslední 1–2 interakce“), nebo se jim dá prominentní místo.
C) Učení v kontextu (ICL)
„Učení v kontextu“ znamená, že historie/příklady vložíš do kontextu tak, aby se model chytil vzoru. V praxi ale často platí, že model
reaguje výrazněji na poslední položky v kontextu (proto bývají v obrázku zvýrazněné novější interakce).
Výsledek tohoto bloku je dole shrnutý jako:
„Vzor se sekvenční historií interakcí H“.
Písmeno H znamená History – tedy „historie“.
3) Prostřední blok: Získávání kandidátů + bootstrapping
Tento blok ukazuje, jak se z historie (H) dostaneš k sadě konkrétních možností, které se potom budou hodnotit a řadit.
Je to rozdělené na dvě části:
Krok 1: Získat (Retrieve)
Nejprve se „vytáhnou“ kandidáti – tedy položky, které připadají v úvahu (na obrázku například 1, 2, 3).
Kandidáti mohou být produkty, témata, odpovědi, dokumenty, varianty řešení… podle toho, co systém dělá.
Krok 2: Bootstrap
Pak přichází důležitá pojistka: bootstrapování kvůli snížení pozičního zkreslení (position bias).
LLM může mít tendenci preferovat položky jen proto, že jsou na začátku seznamu nebo jsou „vidět dřív“.
Proto se stejní kandidáti ukážou modelu v různých pořadích (např. 3–2–1, 1–3–2, 2–1–3).
Pokud model hodnotí opravdu relevanci/kvalitu, měl by dávat podobný výsledek i při změně pořadí.
Výsledek tohoto bloku je dole shrnutý jako:
„Vzor se získanými kandidátskými položkami C“.
Písmeno C znamená Candidates – tedy „kandidáti“.
4) Pravý blok: Řazení s LLM + parsování výstupů
Tady se kandidáti předají jazykovému modelu, který udělá ranking – seřazení od nejlepšího po nejhorší
(v obrázku je ukázka pořadí 2, potom 1, potom 3).
Parsování výstupů
„Parsování výstupů“ znamená, že odpověď od LLM je potřeba převést do jasně použitelného formátu:
například do seznamu, tabulky, JSONu nebo struktury „1. místo / 2. místo / 3. místo“.
Je to praktický krok, aby se s výsledkem dalo dál pracovat automaticky.
Dole vpravo je „Instrukční šablona T“. To je standardní prompt, kterým modelu říkáš:
podle čeho má hodnotit a v jakém formátu má výsledek vrátit.
Písmeno T znamená Template – tedy „šablona“.
Co znamenají H, C, T
- H = historie interakcí (History)
- C = kandidáti, které budeme hodnotit (Candidates)
- T = instrukční šablona pro model (Template)
Hlavní sdělení infografiky
Vezmeš historii uživatele (H), z ní vytáhneš kandidáty (C), promícháš je kvůli pozičnímu zkreslení, a necháš LLM podle instrukční šablony (T) kandidáty seřadit a výsledek strojově zpracuješ.
Praktická poznámka
Bootstrap je v tomto schématu klíčový, protože bez něj může ranking vypadat „chytře“, ale často bude jen odrazem toho, co bylo v seznamu první. Promíchání pořadí pomáhá zkontrolovat, jestli je výsledek stabilní a robustní.
Jak to funguje (princip)
- Rozdělení úkolu na kroky: určíš, jaké fáze musí vzniknout (např. sběr požadavků, návrh, revize).
- Prompty v pořadí: každý krok má svůj prompt a navazuje na předchozí (buď volně, nebo přes konkrétní výstup).
- Iterace a korekce: mezi kroky můžeš upravit zadání, doplnit kontext nebo opravit směr.
- Finální syntéza: poslední prompt složí finální odpověď / artefakt (text, checklist, plán, tabulku).
Proč je to užitečné
- Lepší kontrola: místo jednoho „velkého generování“ máš více menších rozhodovacích bodů a můžeš zasáhnout dřív.
- Vyšší kvalita u komplexních úloh: model se soustředí vždy jen na jednu věc a méně vynechává důležité části.
- Opakovatelnost: jednotlivé kroky můžeš standardizovat jako workflow (stejné kroky, jiná data).
- Snazší ladění: když je výstup špatně, upravíš jen konkrétní krok, ne celý prompt od nuly.
Na co si dát pozor (slabiny)
- Více tokenů / času: více kroků = více volání, více textu, větší náklady.
- Řetězení chyb: když se v raném kroku objeví chyba, může se „propagovat“ dál, pokud ji nezastavíš kontrolním krokem.
- Orchestrace: musíš mít jasno, jak se předávají výsledky mezi kroky (co kopíruješ, co shrnuješ, co jen odkazuješ).
Rozdíl: Sequential Prompting vs. Prompt Chaining
Tyto pojmy se často zaměňují, ale prakticky se dají rozlišit takto:
- Sequential prompting: používáš prompty „po sobě“ jako postup/workflow. Výstup z předchozího kroku
může, ale nemusí být přímo vložen jako vstup do dalšího kroku (někdy stačí, že navazuješ logicky a dáváš nové instrukce). - Prompt chaining: je přísnější varianta, kde se výstup z kroku A explicitně používá jako vstup do kroku B
(doslova ho vkládáš, nebo strukturovaně předáváš dál).
Kdy použít sekvenční promptování
- Komplexní psaní: nejdřív struktura, pak obsah, pak editace, pak kontrola stylu.
- Analýza a doporučení: nejdřív rozbor situace, potom varianty, potom rozhodovací kritéria, potom návrh plánu.
- Vysvětlování: nejdřív definice pojmů, pak příklady, pak shrnutí, pak kontrolní otázky.
- Kontrola kvality: krok „kritický recenzent“ / „auditor“, který ověří konzistenci a chybějící části.
Praktická šablona (workflow)
Níže je obecná kostra, kterou můžeš opakovaně používat. Kroků může být 3–6 podle složitosti:
Krok 1: Ujasnění cíle a vstupů
Úkol: Shrň, co přesně mám dodat, pro koho, v jakém formátu a s jakými omezeními. Pokud něco chybí, polož max. 3 doplňující otázky. Výstup: seznam požadavků + seznam otevřených otázek.
Krok 2: Návrh struktury / plánu
Na základě požadavků navrhni strukturu výstupu (osnovu / kroky / kapitoly). Výstup: struktura + stručné poznámky ke každé části.
Krok 3: Generování první verze
Vygeneruj první verzi podle schválené struktury. Dodrž: délku, tón, formát. Nevymýšlej fakta mimo dodaná data.
Krok 4: Kritická revize
Zkontroluj výstup jako přísný editor: - co chybí - co je nejasné - co je v rozporu - co by mohlo být zavádějící Navrhni konkrétní opravy.
Krok 5: Finální verze
Zapracuj opravy z revize a vrať finální verzi. Na konci přidej krátký checklist, že byly splněny požadavky.