Moderní jazykové modely jsou v mnohém ohromující – dokáží psát, překládat, analyzovat i programovat. Přesto mají jednu výraznou slabinu: složené otázky, které vyžadují několik logických kroků. Pokud se zeptáte „Kdo byl prezidentem Francie v roce, kdy zemřel Picasso?“, model musí nejprve zjistit, kdy Picasso zemřel, a teprve potom hledat francouzského prezidenta pro daný rok. Právě pro tyto situace vznikly techniky jako Self-Ask Prompting a Ask Me Anything (AMA).
Zdroj: Measuring and Narrowing the Compositionality Gap in Language Models (autoři Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, Mike Lewis). ze dne [ 7. října 2022 ].
Co je Self-Ask Prompting?
Self-Ask Prompting (volně přeloženo jako „Sebedotazování“) je technika promptingu pro velké jazykové modely (LLM), kterou v říjnu 2022 popsali výzkumníci Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith a Mike Lewis v článku Measuring and Narrowing the Compositionality Gap in Language Models.
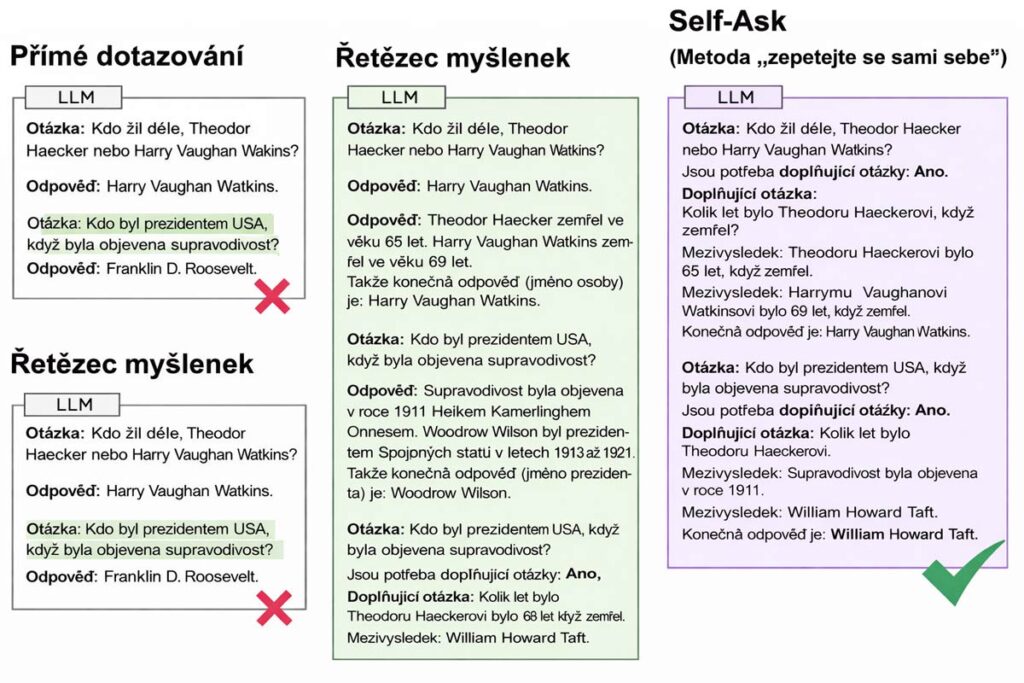
Základní myšlenka je překvapivě jednoduchá: namísto toho, aby model odpověděl na složenou otázku rovnou, nejprve sám sobě položí sérii jednodušších dílčích otázek, na každou z nich si odpoví a teprve poté složí finální odpověď. Model se tak stává zároveň tazatelem i respondentem.
Autoři studie si všimli jevu, který nazvali compositionality gap – tedy mezera v kompozičnosti. Zjistili, že jazykové modely sice znají odpovědi na jednotlivé dílčí fakty, ale nejsou schopny tyto znalosti správně propojit, když jsou dotázány na složenou otázku najednou. Jinými slovy: model ví, kdy Picasso zemřel, a ví, kdo byl tehdy prezidentem Francie, ale přímá složená otázka ho mate. Self-Ask tuto mezeru výrazně zužuje.
Jak Self-Ask Prompting funguje v praxi?
Průběh je strukturovaný a připomíná postup detektiva, který řeší případ krok po kroku. Celý proces lze popsat takto:
1. Identifikace složenosti otázky. Model dostane otázku a nejprve posoudí, zda ji lze zodpovědět přímo, nebo zda vyžaduje více kroků. Pokud potřebuje více kroků, explicitně to oznámí – v promptu se typicky objeví výraz „Are there follow-up questions needed? Yes.“
2. Formulace dílčí otázky. Model si sám sobě položí první dílčí otázku, která je nezbytná pro zodpovězení té hlavní. Tuto otázku označí ve formátu „Follow-up: [otázka]“.
3. Zodpovězení dílčí otázky. Model na svou vlastní otázku ihned odpovídá ve formátu „Intermediate answer: [odpověď]“. V pokročilejších implementacích lze v tomto kroku zapojit i externí vyhledávač nebo databázi pro faktické ověření.
4. Iterace. Kroky 2 a 3 se opakují tak dlouho, dokud má model k dispozici všechny informace potřebné pro finální odpověď.
5. Finální odpověď. Jakmile jsou všechny dílčí otázky zodpovězeny, model je složí do výsledné odpovědi označené „So the final answer is: [odpověď]“.
Celý dialog modelu se sebou samým vypadá přibližně takto: Dostane otázku „Kdo byl prezidentem Francie v roce, kdy zemřel Pablo Picasso?“ Model odpoví: „Potřebuji dílčí informace. Follow-up: Kdy zemřel Pablo Picasso? Intermediate answer: Pablo Picasso zemřel v roce 1973. Follow-up: Kdo byl prezidentem Francie v roce 1973? Intermediate answer: V roce 1973 byl prezidentem Francie Georges Pompidou. So the final answer is: Georges Pompidou.“
Proč to funguje?
Self-Ask Prompting je efektivní z několika důvodů. Za prvé, rozkládá složitý problém na menší, zvládnutelné části – což je ostatně princip, který funguje nejen v AI, ale i v lidském myšlení. Za druhé, explicitní formulace dílčích otázek nutí model být transparentní ohledně svého uvažování, což snižuje riziko halucinací a logických chyb. Za třetí, technika se přirozeně kombinuje s externím vyhledáváním: dílčí otázky lze odesílat do vyhledávače a vrácené výsledky použít jako „Intermediate answers“, čímž model získává přístup k aktuálním faktům.
Ask Me Anything Prompting: Jiný přístup ke stejnému problému
Zatímco Self-Ask řeší problém kompozičnosti otázek, technika Ask Me Anything Prompting (AMA), navržená výzkumníky ze Stanfordovy univerzity, Numbers Station a UW-Madison, si bere na mušku jiný problém: křehkost tradičních promptů.
Tradiční prompty jsou totiž velmi citlivé na přesnou formulaci. Malá změna ve znění instrukce může dramaticky ovlivnit kvalitu výstupu. AMA tento problém řeší elegantním způsobem – místo hledání jednoho dokonalého promptu jich použije mnoho nedokonalých a jejich výstupy agreguje do jednoho spolehlivého výsledku.
Jak AMA funguje?
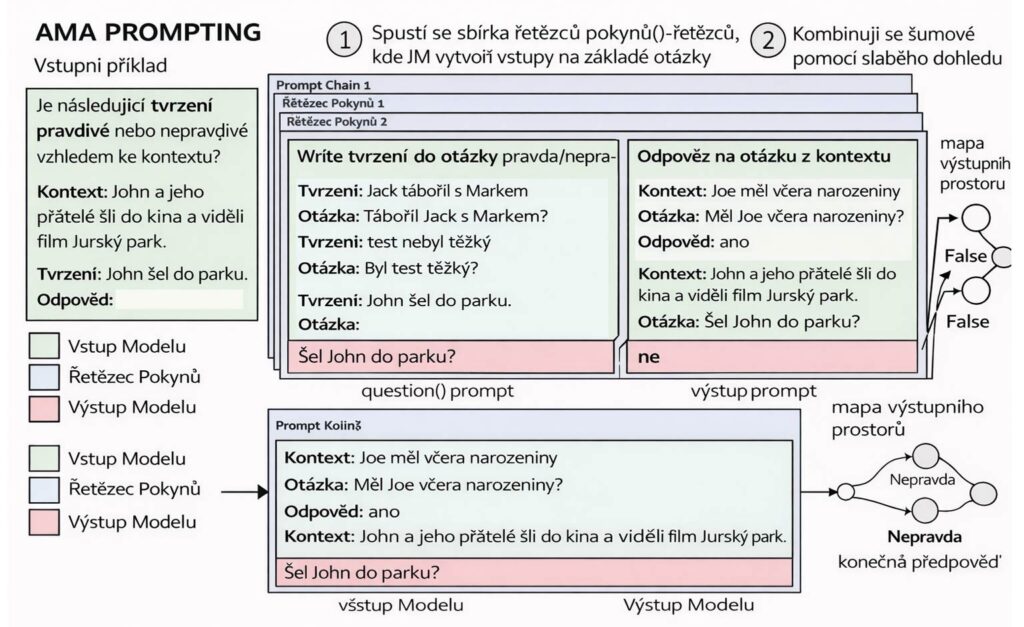
Metoda AMA je postavena na dvou pilířích: přeformátování vstupu a agregace výstupů.
Přeformátování vstupu spočívá v tom, že AMA využívá samotný LLM k rekurzivní transformaci libovolného vstupního textu do formátu otázka-odpověď (QA). Proč právě QA formát? Protože otevřené otázky přirozeně podporují model v generování nuancovanějších a méně kategorických odpovědí než restriktivní formáty jako „Ano/Ne“ nebo výběr z možností.
Konkrétně: model dostane vstupní tvrzení nebo příklad a prostřednictvím dvou řetězených promptů ho převede do QA formátu. První prompt question() přemění vstupní tvrzení na otázku. Druhý prompt answer() na tuto vygenerovanou otázku odpoví. Různé varianty těchto promptů – lišící se například ukázkovými příklady – vedou k různým pohledům na tentýž vstup.
Agregace výstupů je druhým klíčovým krokem. Různé varianty promptů vygenerují různé předpovědi, které mohou být navzájem rozporuplné nebo nepřesné – jsou to takzvaná „šumová hlasování“. AMA tyto hlasy agreguje pomocí techniky slabého dohledu (weak supervision), která dokáže kombinovat více nepřesných predikcí bez potřeby dodatečně označených trénovacích dat. Výsledkem je spolehlivější predikce, než jakou by poskytl jakýkoliv jednotlivý prompt.
Kde se obě techniky liší a kde se potkávají
Self-Ask a AMA přistupují k problémům LLM z různých úhlů, ale sdílejí společnou filozofii: neptat se modelu jednou přímo, ale zorganizovat jeho myšlení do strukturovanějšího procesu.
Self-Ask je primárně určen pro složené faktické otázky, kde je třeba propojit více informací. Je lineární a sekvenční – každý krok staví na předchozím. AMA naproti tomu řeší spolehlivost modelu napříč různými typy úloh tím, že paralelně generuje více pohledů a tyto pohledy demokraticky „přehlasuje“ do výsledku.
Obě techniky ovšem vedou ke stejnému cíli: překonat inherentní omezení jazykových modelů nikoli jejich přetrénováním, ale chytřejším způsobem kladení otázek. Ukazují, že velká část potenciálu LLM tkví ne v samotném modelu, ale ve způsobu, jakým s ním komunikujeme.
Zdroj: Ask Me Anything: A simple strategy for prompting language models (autoři Simran Arora, Avanika Narayan, Mayee F. Chen, Laurel Orr, Neel Guha, Kush Bhatia, Ines Chami, Frederic Sala, Christopher Ré). ze dne [ 5. října 2022 – revize 20. listopadu 2022 ].
Výsledky: Čísla, která mluví za vše
AMA nebyla jen teoretickým konceptem – výzkumníci ji důkladně otestovali v praxi. Metoda byla hodnocena napříč několika rodinami open-source modelů: EleutherAI, BLOOM, OPT a T0, a to v širokém rozsahu velikostí od 125 milionů až po 175 miliard parametrů. Výsledky byly jednoznačné: AMA dosáhla průměrného zlepšení výkonu o 10,2 % oproti základnímu few-shot přístupu (tedy standardnímu promptingu s několika ukázkovými příklady).
Nejpozoruhodnější výsledek přineslo srovnání modelu GPT-J-6B s mnohem větším GPT-3-175B. GPT-J má přibližně 6 miliard parametrů, zatímco GPT-3 jich má 175 miliard – tedy téměř třicetkrát více. Přesto se GPT-J s využitím AMA vyrovnal nebo dokonce překonal výkon GPT-3 v 15 z 20 populárních benchmarků. Jinými slovy: chytřejší způsob promptingu dokázal kompenzovat obrovský rozdíl v parametrech modelu.
Tento výsledek má zásadní praktické implikace. Ukazuje, že nasazení špičkových AI schopností nevyžaduje nutně přístup k největším a nejdražším modelům. Menší open-source modely, které si firmy mohou provozovat vlastní infrastruktuře, mohou při správném promptovacím přístupu dosahovat výsledků srovnatelných s komerčními giganty.
Proč je to důležité pro budoucnost AI v praxi?
Autoři článku uzavírají s dvěma klíčovými závěry. Za prvé, AMA demokratizuje přístup k výkonnému AI – snižuje potřebu precizního a pracného ladění promptů, což byl doposud jeden z největších praktických problémů nasazení LLM ve firmách. Není třeba být expertem na prompting, aby model podával spolehlivé výsledky. Za druhé, AMA představuje škálovatelnou metodu agregace promptů, kterou lze aplikovat napříč různými typy úloh a modelů bez nutnosti přístupu k označeným trénovacím datům.
Celý kód metody AMA je veřejně dostupný, což umožňuje komunitě techniku dále rozvíjet, testovat a přizpůsobovat konkrétním aplikacím. Pro ty, kteří chtějí metodu prozkoumat nebo implementovat ve vlastních projektech, je kód k dispozici na GitHubu: github.com/HazyResearch/ama_prompting.
Vladimír Matula
Vladimír Matula se v digitálním marketingu pohybuje od roku 2008. Svou expertízu staví na pevných základech z předních českých agentur, kde se specializoval na tvorbu webů, ecommerce, SEO a webovou analytiku. V roce 2012 založil marketingovou agenturu DIVERSITY PROMOTION s.r.o., kde nabízí online marketingové služby, tvorbu webů na WordPress, tvorbu eshopů na platformě Shoptet, Web design a AI marketing. Generativní AI integruje do klíčových procesů – od hloubkové analýzy dat, SEO a konverzního copywritingu podle ověřených vzorců až po automatizaci rutinních úkolů, které přináší úsporu času a vyšší kvalitu výstupů nejen jemu, ale i jeho klientům.
